AI 基础概念
模型调用快速入门
准备工作
注册链接:智谱AI注册
我们的调用模型的时候需要使用 API Key 进行身份验证。所以需要参加一个 API Key。创建完后避免暴露:创建API Key地址
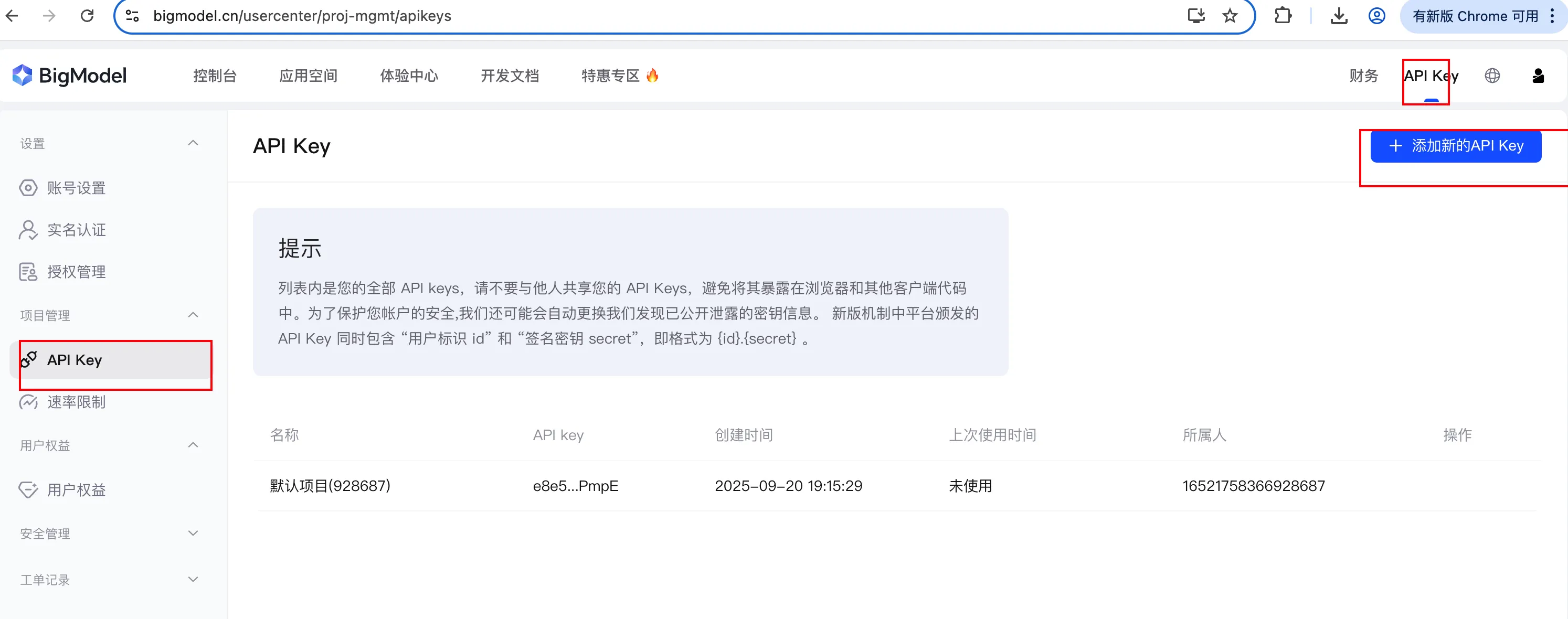
创建好后,复制对应的 key:
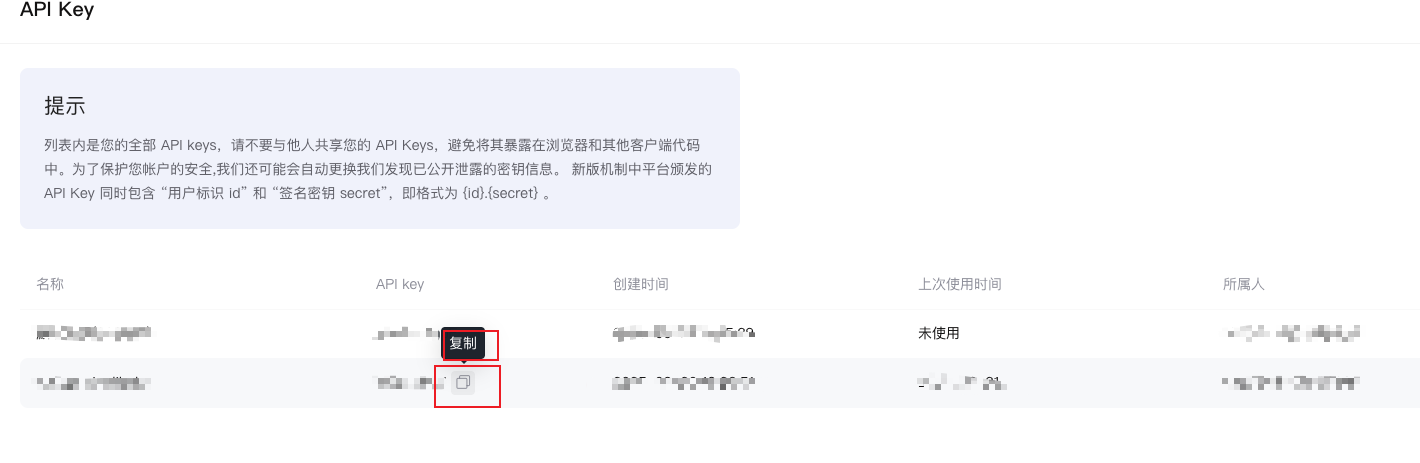
接口调用
我们先使用接口的调用下模型测试下 key 是否正常可用,同时也是也是让大家熟悉原始的模型调用。后面我们在使用 Spring AI Alibaba 的时候也更容易理解。
每个模型都有自己的 API 文档。我们去看下智谱 AI 的 API 文档。(可以先在官网上测试接口):智谱API文档
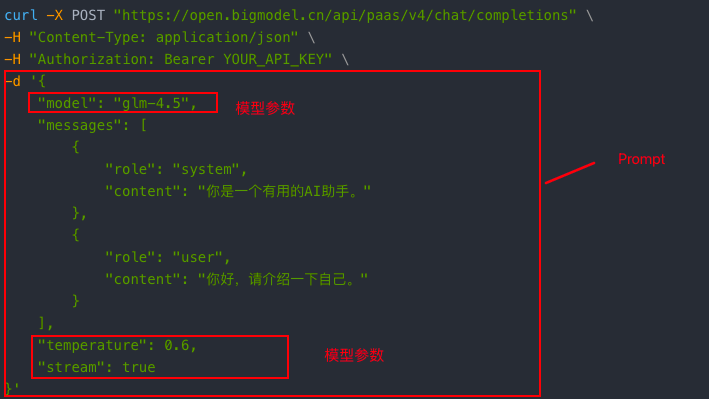
curl -X POST "https://open.bigmodel.cn/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "glm-4.5",
"messages": [
{
"role": "system",
"content": "你是一个有用的AI助手。"
},
{
"role": "user",
"content": "你好,请介绍一下自己。"
}
],
"temperature": 0.6,
"stream": true
}'
把 curl 复制到 apifox,然后把自己的 API Key 替换上去。
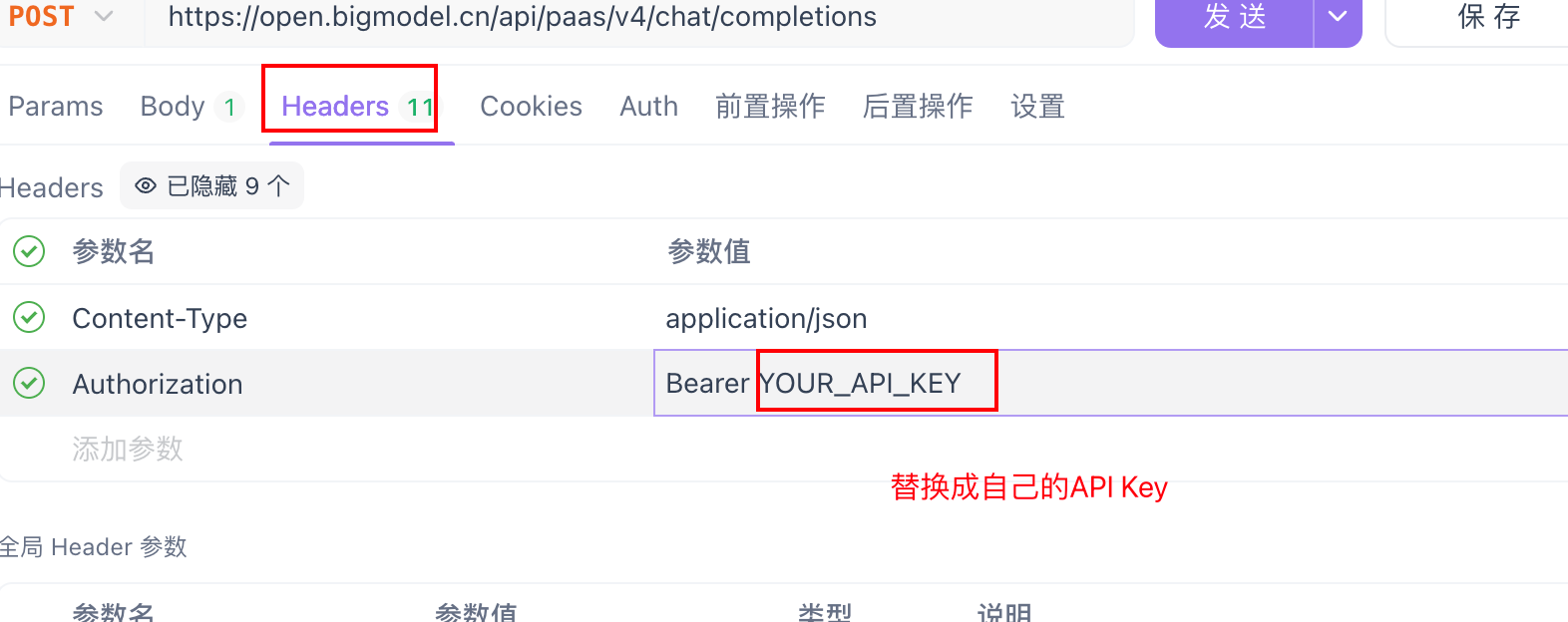
由于上面请求的 stream 是 true。所以结果是流式输出。

如果想在 ApiFox 上看合并的结果,可以自定义提取规则后点击自动合并。我们是需要把 choices 的第一个元素里的 delta 字段的 content 的内容合并在一起,所以提取规则可以写成:$.choices[0].delta.content
具体规则可以看:提取规则
相关概念
- LLM - LLM 是大型语言模型(Large Language Model)的缩写。是一种通过海量文本数据训练,能够理解和生成人类语言的人工智能系统
- token - AI 大模型调用中,模型处理文本的基本单位。各家算法切字逻辑,但是大致一个 token 约等于一个汉字左右。 具体可以看各家厂商提供的切词可视化工具 (OpenAI:https://platform.openai.com/tokenizer 文心一言:https://console.bce.baidu.com/support/#/tokenizer 阿里千问:https://dashscope.console.aliyun.com/tokenizer)
- 模型参数 - 调用模式时可以设置的一些参数,每个模型支持的参数会有一些参数,都是大部分参数都是相同的。常见参数:
- Temperature (温度):控制生成文本的随机性。值越低(如 0.2),输出越确定、保守和专注;值越高(如 0.9),输出越具有创造性和多样性,但也可能更不连贯
- Top-p (核采样):与 Temperature 类似,用于控制采样的多样性。它从累积概率超过阈值 p 的最可能候选词中随机选择。较低的值(如 0.5)限制选择范围,输出更可预测;较高的值(如 0.9)则扩大选择范围
- Max Tokens (最大生成长度):限制模型单次响应所能生成的最大 token 数量。设置过短可能导致回答被截断。
- 流式响应 - 类似于我们使用 Deepseek 时 AI 给我们一个字一个字的回答的效果。 目前流式响应主要是使用 SSE 技术实现的。
- message - 目前主要是 4 种消息角色。
- system(系统消息,用于设定 AI 的行为和角色)
- user(用户消息,来自用户的输入)
- assistant(助手消息,来自 AI 的回复)
- tool(工具调用消息)
- prompt - Prompt(提示词) 是您传递给 AI 模型的指令或问题。简单来说,Prompt 是你用来告诉 AI“做什么”和“怎么做”的话。
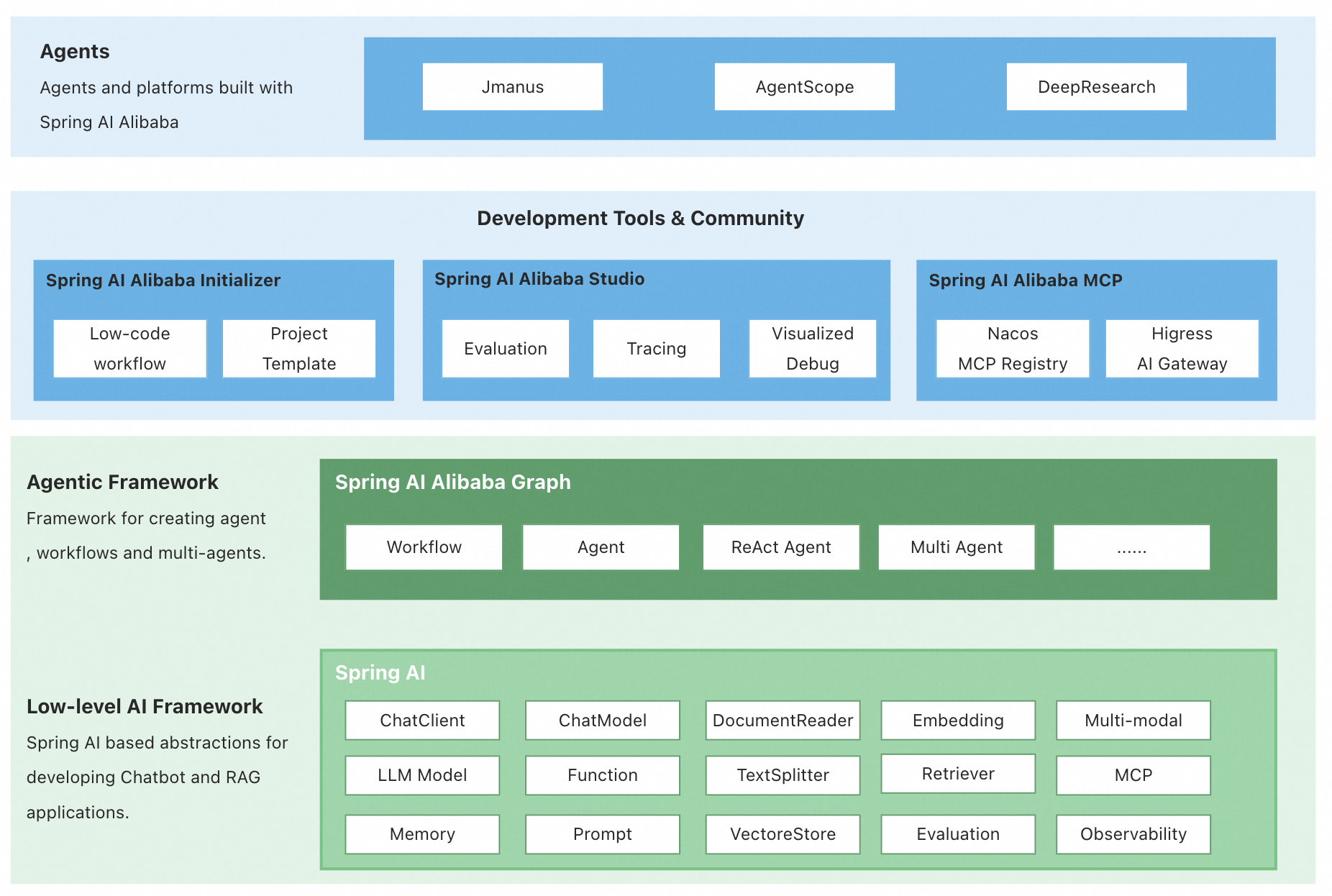
SpringAIAlibaba 概述
它本质上是一个基于 Spring AI 抽象层的“增强插件集”,其核心价值在于提供了统一、便捷的接口,让你可以灵活地选择和切换底层模型。(并不是使用了 SpringAIAlibaba 就必须和阿里千问模型等深度绑定)
我们去学习它最主要的一个核心原因是 Graph:用于编排多智能体与工作流 (Multi-Agent/Workflow)
官方文档:https://java2ai.com/docs/1.0.0.2/overview/?spm=4347728f.6476bf87.0.0.a3c1556b0YIohP
快速入门
目标
使用 Spring AI Alibaba 实现模型调用。调用/zhipuai/simple 接口传入一个问题就能调用实现 AI 模型的调用,把模型的答案返回。
准备工作
把 API Key 写入环境变量
为了避免把我们的 API Key 明文写入代码或者配置文件中。我们可以把 API Key 存储到系统的环境变量中。然后工程中去引用对应的环境变量。
| 系统 | 写入方式 |
|---|---|
| windows | 通过系统属性 GUI 操作,添加环境变量 ZHIPU_KEY 值为 你的 API Key |
| macos | 在 ~/.bashrc, ~/.zshrc 或 ~/.profile 中写入 export ZHIPU_KEY=" 创建的 key" |
创建父工程
为了便于我们管理依赖。我们先创建个父工程。
版本说明:
- JDK:17 (官方最低要求 17)
- SpringAI :1.0.0
- SpringBoot : 3.4.0
- Spring AI Alibaba : 1.0.0.4
pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sangeng</groupId>
<artifactId>sangeng-springai-examples</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging>
<properties>
<project.version>1.0-SNAPSHOT</project.version>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-ai.version>1.0.0</spring-ai.version>
<spring-ai-alibaba.version>1.0.0.4</spring-ai-alibaba.version>
<!-- Spring Boot -->
<spring-boot.version>3.4.0</spring-boot.version>
<!-- maven plugin -->
<maven-deploy-plugin.version>3.1.1</maven-deploy-plugin.version>
<flatten-maven-plugin.version>1.3.0</flatten-maven-plugin.version>
<maven-compiler-plugin.version>3.8.1</maven-compiler-plugin.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>${spring-ai-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-deploy-plugin</artifactId>
<version>${maven-deploy-plugin.version}</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven-compiler-plugin.version}</version>
<configuration>
<release>17</release>
<compilerArgs>
<compilerArg>-parameters</compilerArg>
</compilerArgs>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>flatten-maven-plugin</artifactId>
<version>${flatten-maven-plugin.version}</version>
<inherited>true</inherited>
<executions>
<execution>
<id>flatten</id>
<phase>process-resources</phase>
<goals>
<goal>flatten</goal>
</goals>
<configuration>
<updatePomFile>true</updatePomFile>
<flattenMode>ossrh</flattenMode>
<pomElements>
<distributionManagement>remove</distributionManagement>
<dependencyManagement>remove</dependencyManagement>
<repositories>remove</repositories>
<scm>keep</scm>
<url>keep</url>
<organization>resolve</organization>
</pomElements>
</configuration>
</execution>
<execution>
<id>flatten.clean</id>
<phase>clean</phase>
<goals>
<goal>clean</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
创建子工程
01_springai-alibaba-quick-start
添加依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
</dependencies>
由于我们要调用的是智谱 AI,所以需要引入 spring-ai-starter-model-zhipuai。如果用的是别的 AI 模型引入对应的启动器即可
- deepseek -
spring-ai-starter-model-deepseek - 千问 -
spring-ai-alibaba-starter-dashscope - OpenAI -
spring-ai-starter-model-openai
修改配置
application.yaml:
server:
port: 8080
spring:
ai:
zhipuai:
api-key: ${ZHIPU_KEY} # 配置 API Key
base-url: "https://open.bigmodel.cn/api/paas" # 配置 模型地址
chat:
options:
model: glm-4.5
创建 SpringBoot 启动类
package com.sangeng;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ZhipuAIApplication {
public static void main(String[] args) {
SpringApplication.run(ZhipuAIApplication.class, args);
}
}
代码编写
@RestController
@RequestMapping("/zhipuai")
public class ZhipuChatController {
private final ChatModel chatModel;
// 通过构造器注入 ChatModel
public ZhipuChatController(ChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/simple")
public String simpleChat(@RequestParam(name = "query") String query) {
// 调用ChatModel 的call方法传入问题完成模型调用
return chatModel.call(query);
}
}
测试
http://localhost:8080/zhipuai/simple?query=你是谁
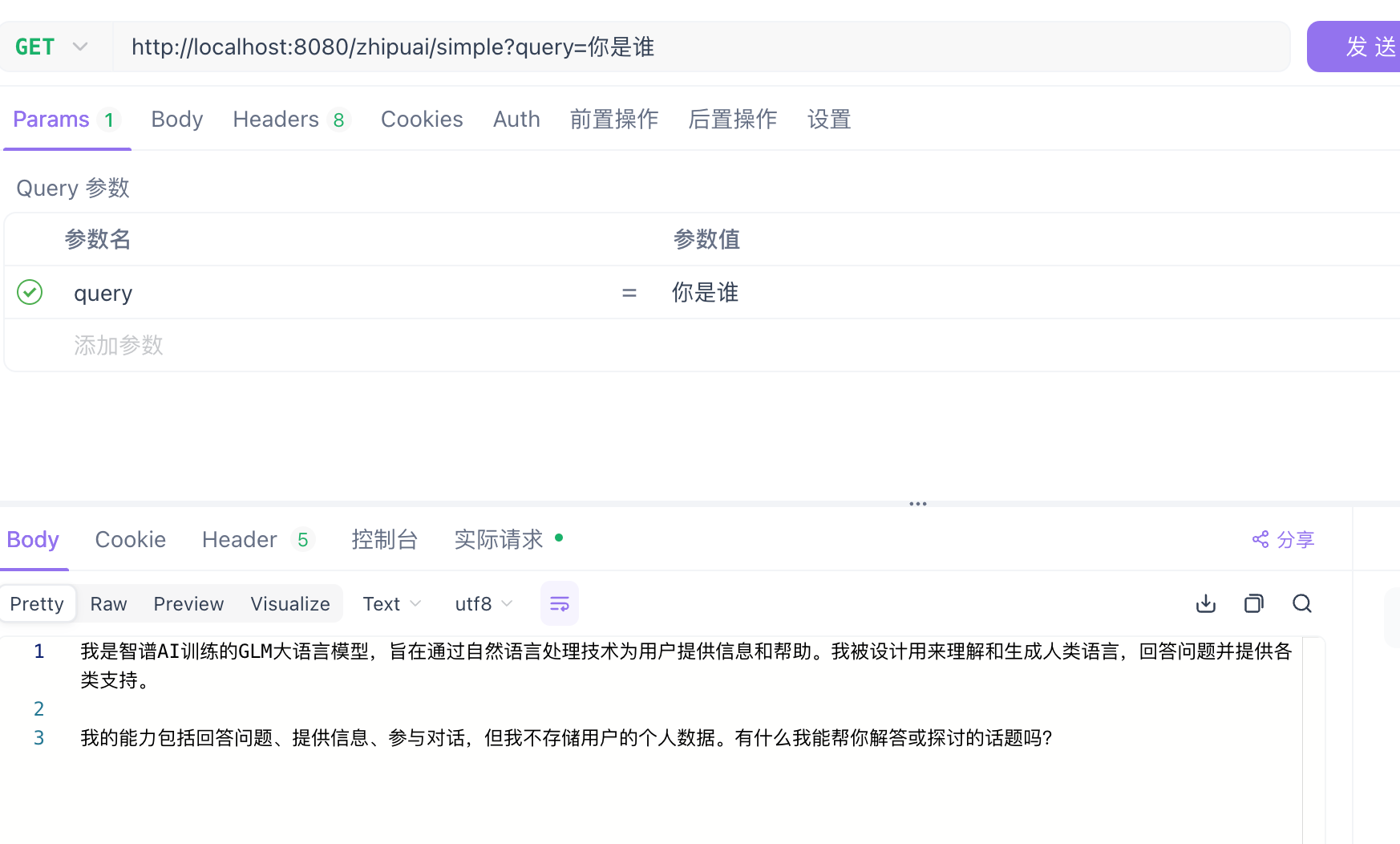
原理初探
我们可以在 org.springframework.ai.zhipuai.api.ZhiPuAiApi#chatCompletionEntity 打上断点进行调试
核心 API
Message
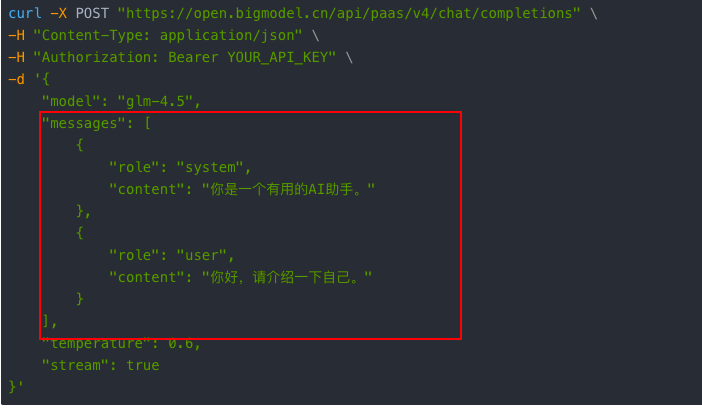
我们来看请求中的这部分内容:
messages 是一个数组,其中的每个对象都有 role 和 content 两个属性。这个对象在 SpringAI 中就被抽象成 Message。
我们先来看下智谱的文档中对 messages 的介绍:

再来看下 SpringAI 中的设计的 Message 的继承体系:
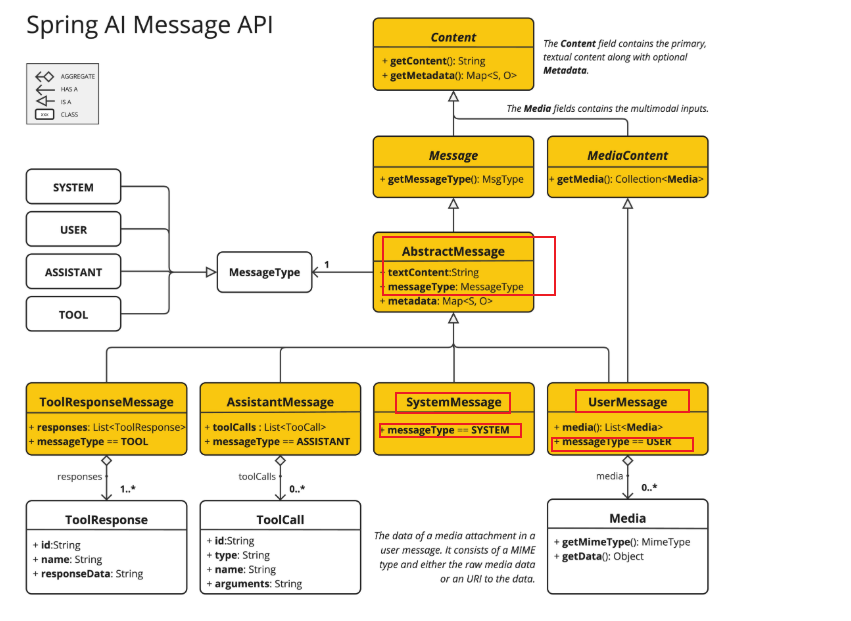
从这个继承关系中我们可以看到 AbstractMessage 相对于把我们接口中看到的 role 字段抽象成 messageType 属性。content 字段抽象成 textContent 属性。
MessageType 定义的枚举源码如下:
public enum MessageType {
USER("user"),
ASSISTANT("assistant"),
SYSTEM("system"),
TOOL("tool");
}
也是和我们目前 role 可以使用的 4 种值对应。
这个时候我们回过头去看 call 方法的支持的参数类型:
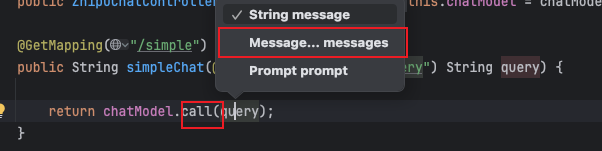
你就能理解为什么它可以支持传 Message 的可变参的含义了。 相对于就是传入了一个 Message 列表。这个列表本质上会转化为请求中的 messages。
所以如果想使改造入门案例的代码和下面的 curl 调用相同的效果应该怎么实现呢?
curl -X POST "https://open.bigmodel.cn/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "glm-4.5",
"messages": [
{
"role": "system",
"content": "你是一个有用的AI助手。"
},
{
"role": "user",
"content": "你好,请介绍一下自己。"
}
]
}'
@GetMapping("/message")
public String message(@RequestParam(name = "query") String query) {
SystemMessage systemMessage = new SystemMessage("你是一个有用的AI助手。");
UserMessage userMessage = new UserMessage(query);
// 调用模型
return chatModel.call(systemMessage,userMessage);
}
Prompt
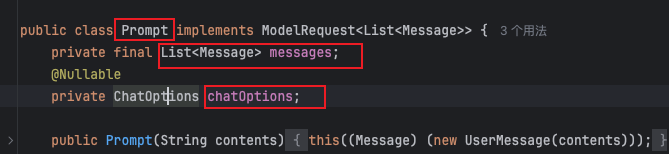
Prompt 提示词 是引导 AI 模型生成特定输出的输入格式,Prompt 的设计和措辞会显著影响模型的响应。
在 SpringAI 中,是把模型参数和消息列表的组合抽象为 Prompt。
所以 Prompt 中主要是有以下两个属性:messages 和 chatOptions:
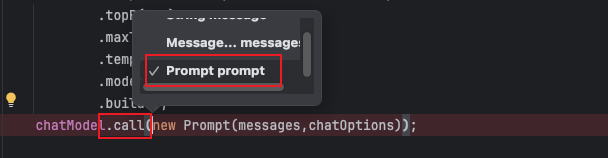
这个时候我们再看下 call 方法支持的参数类型中就有 Prompt 类型的就更容易理解了。
接下去我们聊下 ChatOptions:
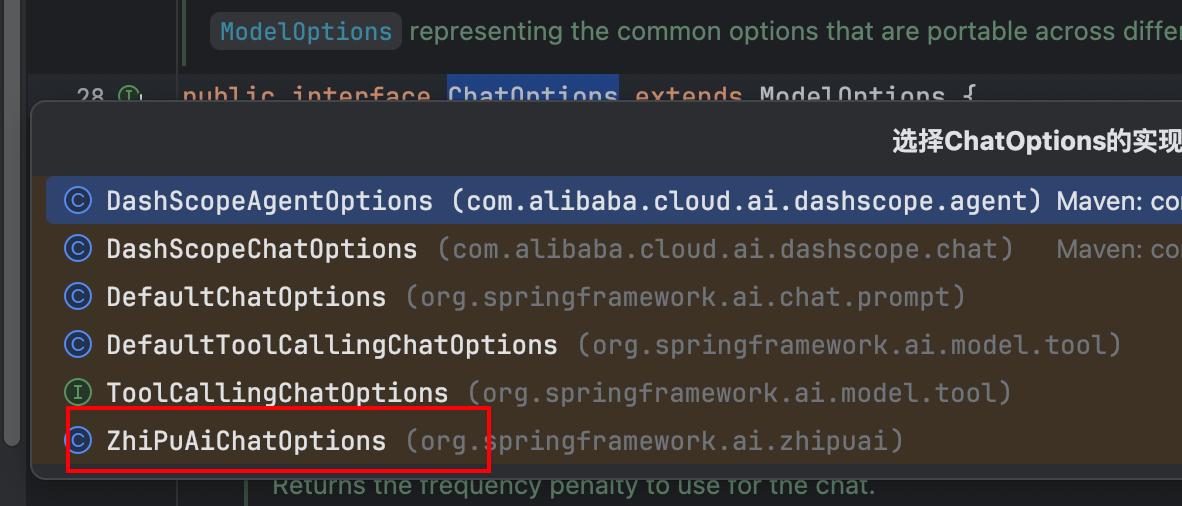
我们前面讲过不同厂商的模型支持的模型参数不同,当然也有些参数上普遍都支持的。所以 SpringAI 在设计的时候把共有的模型参数都设计到了 ChatOptions 中。
而每个模型厂商可以创建自己的 ChatOptions 实现定义厂商支持的模型参数。
所以我们看下当前项目中 ChatOptions 的实现有哪些,就发现了 ZhiPuAiChatOptions:
ZhiPuAiChatOptions 对象的创建
ZhiPuAiChatOptions zhiPuAiChatOptions = new ZhiPuAiChatOptions();
zhiPuAiChatOptions.setModel("glm-4.5");
zhiPuAiChatOptions.setTemperature(0.0);
zhiPuAiChatOptions.setMaxTokens(15536);
另外一种创建 ChatOptions 的方式
ZhiPuAiChatOptions chatOptions = ZhiPuAiChatOptions.builder()
.model("glm-4.5")
.maxTokens(15536)
.temperature(0.0)
.build();
所以如果想使改造入门案例的代码和下面的 curl 调用相同的效果应该怎么实现呢?
curl -X POST "https://open.bigmodel.cn/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "glm-4.5",
"messages": [
{
"role": "system",
"content": "你是一个有用的AI助手。"
},
{
"role": "user",
"content": "你好,请介绍一下自己。"
}
],
"temperature": 0.0,
"maxTokens":15536
}'
@GetMapping("/chatOptions")
public ChatResponse chatOptions(@RequestParam(name = "query") String query) {
SystemMessage systemMessage = new SystemMessage("你是一个有用的AI助手。");
UserMessage userMessage = new UserMessage(query);
ZhiPuAiChatOptions zhiPuAiChatOptions = new ZhiPuAiChatOptions();
zhiPuAiChatOptions.setModel("glm-4.5");
zhiPuAiChatOptions.setTemperature(0.0);
zhiPuAiChatOptions.setMaxTokens(15536);
// 调用模型
return chatModel.call(new Prompt(List.of(systemMessage,userMessage),zhiPuAiChatOptions));
}
ChatModel
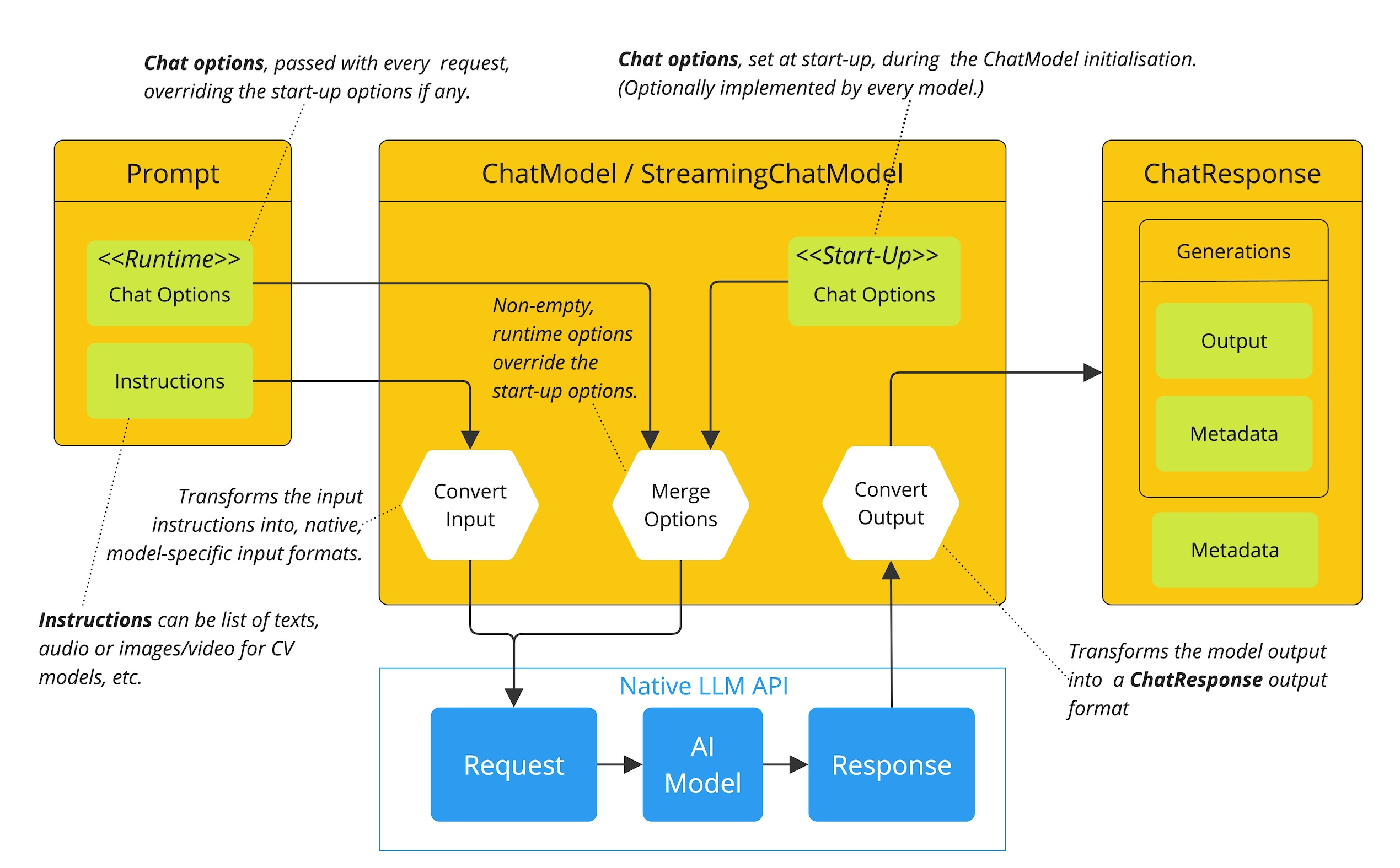
从图中可以看出 ChatModel API 让应用开发者可以非常方便的与 AI 模型进行文本交互,它抽象了应用与模型交互的过程,包括使用 Prompt 作为输入,使用 ChatResponse 作为输出等。
对象获取
引入模型的启动器后直接从容器中注入即可
@RestController
@RequestMapping("/zhipuai")
public class ZhipuChatController {
private final ChatModel chatModel;
// 通过构造器注入 ChatModel
public ZhipuChatController(ChatModel chatModel) {
this.chatModel = chatModel;
}
}
模型调用
同步响应
@GetMapping("/simple")
public String simpleChat(@RequestParam(name = "query") String query) {
return chatModel.call(query);
}
流式响应
@GetMapping("/stream/chat")
public Flux<String> stream(@RequestParam(name = "query") String query) {
return chatModel.stream(query);
}
乱码问题解决:
server:
servlet:
encoding:
charset: UTF-8
enabled: true
force: true
ChatClient
概述
虽然我们可以使用 ChatModel 去调用模型。但是它的使用方法还是有点繁琐的,。SpringAI 为我们提供了 ChatClient 来让我们的使用更加简便,并且有一些更高级的功能。
基础功能:
- 定制和组装模型的输入(Prompt)
- 格式化解析模型的输出(Structured Output)
- 调整模型交互参数(ChatOptions)
- ....
并且它还提供了更多的高级功能:
- 聊天记忆(Chat Memory)
- 工具/函数调用(Function Calling)
- RAG
- ....
创建 ChatClient
直接从容器中注入 ChatClient.Builder
@RestController
public class ChatController {
private final ChatClient chatClient;
public ChatController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
}
或者自己创建 ChatClient.Builder 来构造 ChatClient
@RestController
@RequestMapping("/chatclient")
public class ZhipuChatClientController {
private final ChatClient chatClient;
public ZhipuChatClientController(ChatModel chatModel) {
this.chatClient = ChatClient.builder(chatModel)
.build();
}
}
调用模型并处理响应
返回字符串
@RestController
@RequestMapping("/chatclient")
public class ZhipuChatClientController {
private final ChatClient chatClient;
public ZhipuChatClientController(ChatModel chatModel) {
this.chatClient = ChatClient.builder(chatModel)
.build();
}
@GetMapping("/simple")
public String simpleChat(@RequestParam(name = "query") String query) {
ZhiPuAiChatOptions chatOptions = ZhiPuAiChatOptions.builder()
.maxTokens(15536)
.temperature(0.0)
.model("glm-4.5")
.build();
return chatClient.prompt()
.system("你是一个有用的AI助手。")
.user("你好,请介绍一下自己。")
.options(chatOptions)
.call().content();
}
}
返回 ChatResponse
ZhiPuAiChatOptions chatOptions = ZhiPuAiChatOptions.builder()
.maxTokens(15536)
.temperature(0.0)
.model("glm-4.5")
.build();
ChatResponse chatResponse = chatClient.prompt()
.system("你是一个有用的AI助手。")
.user("你好,请介绍一下自己。")
.options(chatOptions)
.call()
.chatResponse();
响应数据转化成实体
我们在实际开发过程中会更希望模型返回的数据是结构话的数据,这样我们才更好对数据去处理。目前我们最熟悉的结构化数据就是 json 格式,并且我们希望能把 json 直接转化成 bean 对象更方便我们使用。
例如,我们需要让 AI 随机生成一本书,要有书名和作者。并且我们希望结果能直接转化成一个 Book 对象供我们使用。那么我们只需要先定义好 Book 类:
@Data
public class Book {
private String name;
private String author;
}
然后在使用 chatClient 调用完 call 方法后调用 entity 方法传入要转化类的字节码对象即可。
@GetMapping("/response")
public Book response() {
return chatClient.prompt()
.user("给我随机生成一本书,要求书名和作者都是中文")
.call().entity(Book.class);
}
结果测试
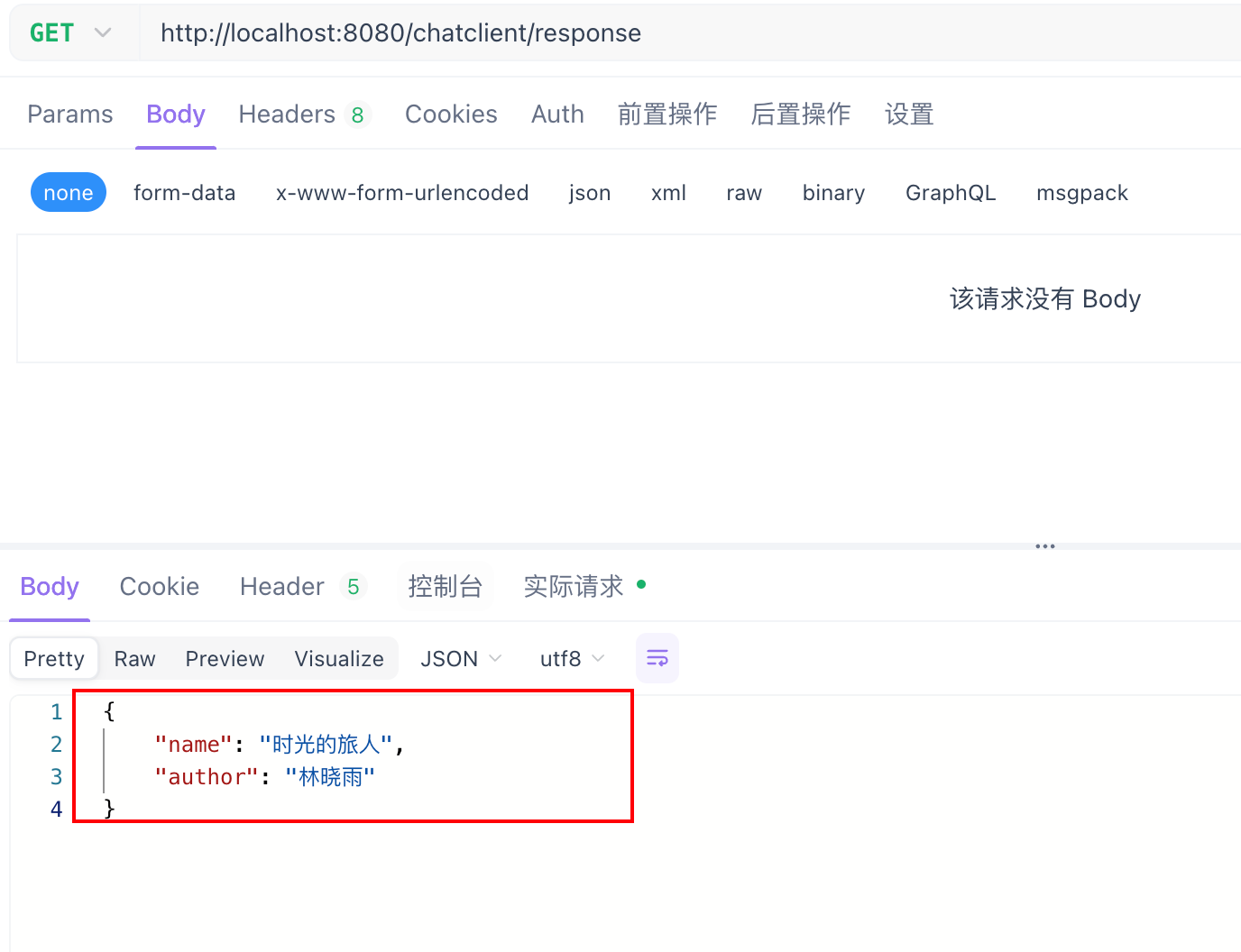
但是我们也要理解他的原理。
前面我们讲过模型调用的本质就是调用模型的接口。所以想知道它是怎么实现的只要看下他在给模型发送请求的时候究竟发送了什么就知道了。
我们可以在 ZhiPuAiApi 的 chatCompletionEntity 方法中打上断点。
我们可以看到本质上他其实就是使用 RestClient 发送请求。
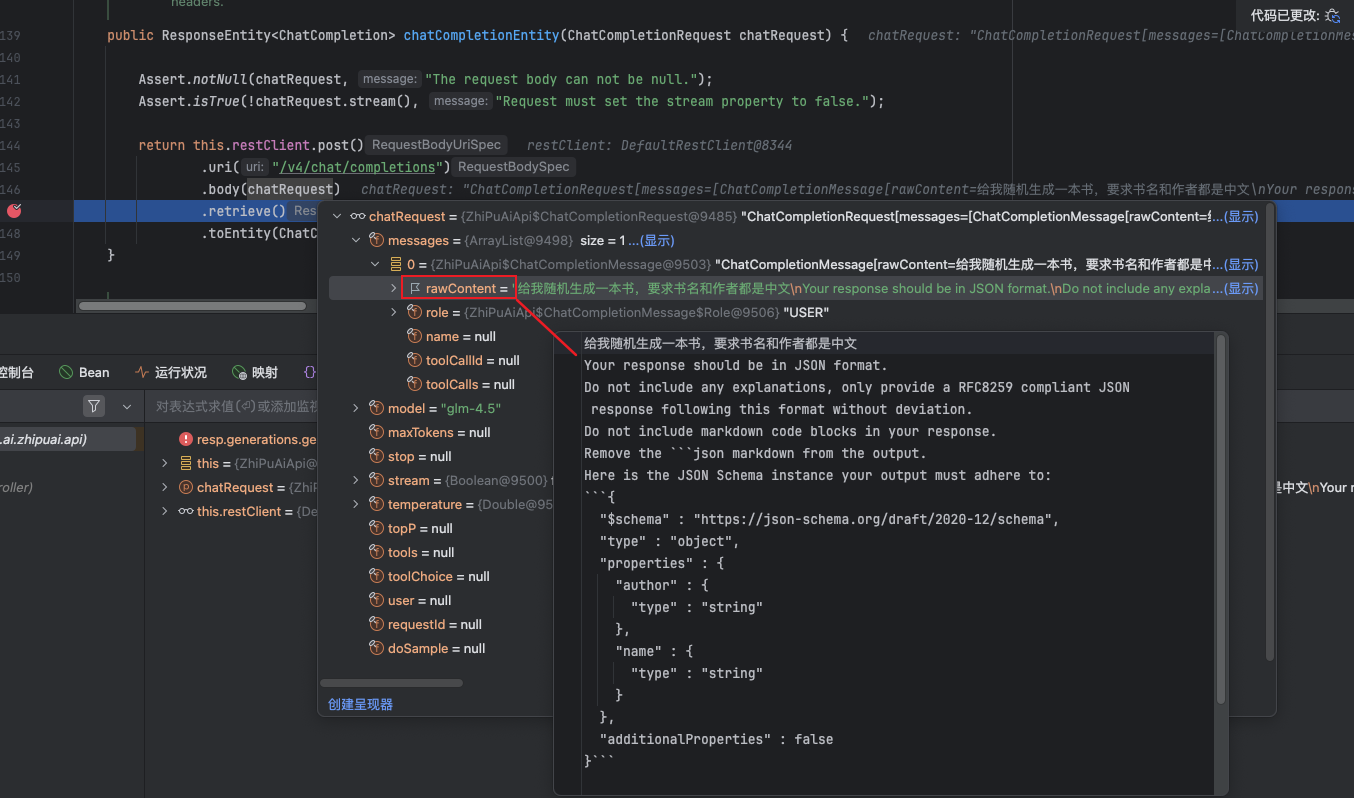
从这里我们可以看到请求中包含了一个 UserMessage,这个 UserMessage 的内容实际上就是在我们的设置的 message 的基础上又加了一段提示词。这个提示词主要就是告诉模型,要求回复的格式是 JSON 格式。并且还告诉了模型我们的 Json 要求有哪些字段,字段的类型是什么。
给我随机生成一本书,要求书名和作者都是中文
Your response should be in JSON format.
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.
Do not include markdown code blocks in your response.
Remove the ```json markdown from the output.
Here is the JSON Schema instance your output must adhere to:
```{
"$schema" : "https://json-schema.org/draft/2020-12/schema",
"type" : "object",
"properties" : {
"author" : {
"type" : "string"
},
"name" : {
"type" : "string"
}
},
"additionalProperties" : false
}```
响应数据流式返回
使用 stream 方法调用模型
@GetMapping(value = "/stream")
public Flux<String> stream() {
return chatClient.prompt()
.user("给我随机生成一本书,要求书名和作者都是中文")
.stream().content();
}
Advisors
概述
Spring AI Advisors 是 Spring AI 框架中的核心拦截器组件,专门用于处理和增强 AI 应用程序中的请求与响应流。其设计和过滤器拦截器非常类似。
优势:
- 将常见的生成式 AI 模式(如对话记忆、敏感词过滤、RAG 检索)打包成可重用单元,简化开发流程
- 创建可跨不同模型和用例工作的可重用转换组件,提升代码灵活性
Advisor 增强流程如下:
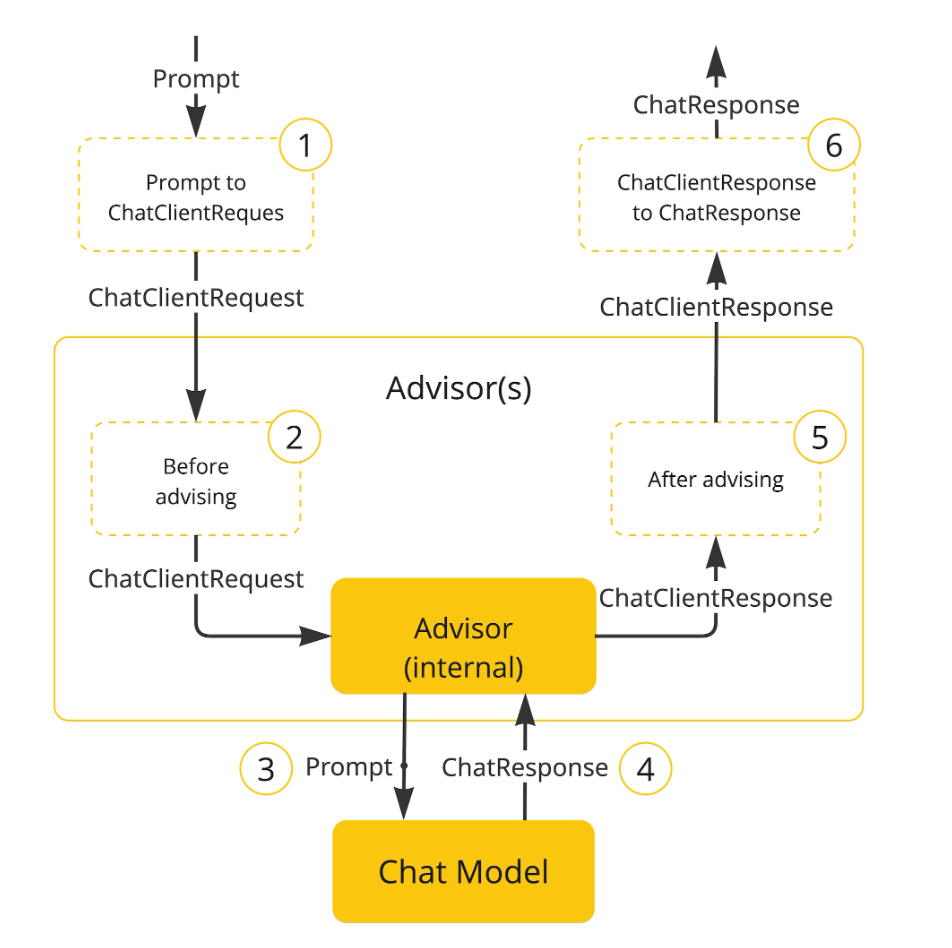
继承体系
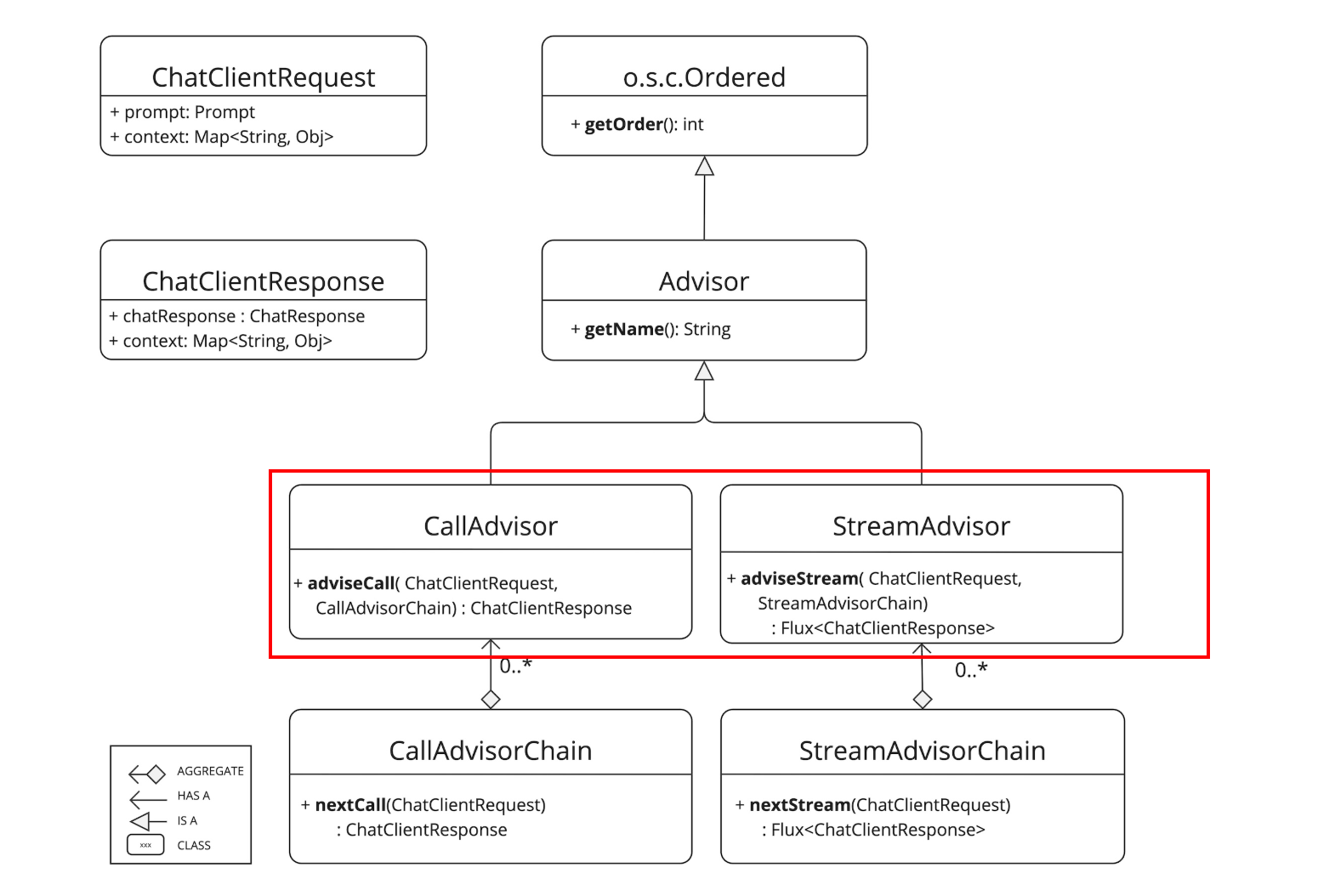
如果我们需要对同步调用进行增强可以使用 CallAdvisor。如果是对流式调用 (响应式调用) 进行增强可以使用 StreamAdvisor。
快速入门
添加两个自定义的 Advisor 进行增强,我们只需要实现 CallAdvisor 接口重写其中的方法即可。
adviseCall 方法参数中的 chatClientRequest 是封装了 AI 请求的对象,我们可以在 Advisor 方法中对其进行增强。
adviseCall 方法参数中的 callAdvisorChain 可以让我们对当前的 AI 请求进行放行,并且返回 ChatClientResponse。我们可以增强 ChatClientResponse 后再返回。
package com.sangeng.advisor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.CallAdvisor;
import org.springframework.ai.chat.client.advisor.api.CallAdvisorChain;
@Slf4j
public class SGCallAdvisor1 implements CallAdvisor {
/**
*
* @param chatClientRequest 请求
* @param callAdvisorChain 增强链,可以用来放行AI请求到下一个Advisor
* @return
*/
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
log.info("SGCallAdvisor1 请求");
ChatClientResponse chatClientResponse = callAdvisorChain.nextCall(chatClientRequest);
log.info("SGCallAdvisor1 响应");
return chatClientResponse;
}
@Override
public String getName() {
return "SGCallAdvisor1";
}
@Override
public int getOrder() {
return 0;
}
}
package com.sangeng.advisor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.CallAdvisor;
import org.springframework.ai.chat.client.advisor.api.CallAdvisorChain;
@Slf4j
public class SGCallAdvisor2 implements CallAdvisor {
/**
*
* @param chatClientRequest 请求
* @param callAdvisorChain 增强链,可以用来放行AI请求到下一个Advisor
* @return
*/
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
log.info("SGCallAdvisor2 请求");
ChatClientResponse chatClientResponse = callAdvisorChain.nextCall(chatClientRequest);
log.info("SGCallAdvisor2 响应");
return chatClientResponse;
}
@Override
public String getName() {
return "SGCallAdvisor2";
}
@Override
public int getOrder() {
return 0;
}
}
给 ChatClient 添加 Advisor
package com.sangeng.controller;
import com.sangeng.advisor.SGCallAdvisor1;
import com.sangeng.advisor.SGCallAdvisor2;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.zhipuai.ZhiPuAiChatOptions;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("/advisor")
public class AdvisorController {
private final ChatClient chatClient;
public AdvisorController(ChatModel chatModel) {
this.chatClient = ChatClient.builder(chatModel)
.build();
}
@GetMapping("/simple")
public String simpleChat(@RequestParam(name = "query") String query) {
ZhiPuAiChatOptions chatOptions = ZhiPuAiChatOptions.builder()
.maxTokens(15536)
.temperature(0.0)
.model("glm-4.5")
.build();
return chatClient.prompt()
.system("你是一个有用的AI助手。")
.user(query)
.advisors(new SGCallAdvisor1(),new SGCallAdvisor2())
.options(chatOptions)
.call().content();
}
}
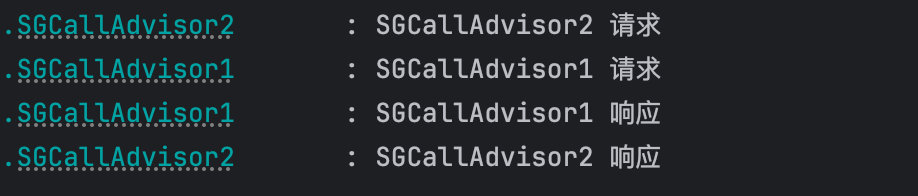
调用接口我们可以看到如下的打印信息
调整 Advisor 顺序
如果我们想调整 Advisor 在 Advisor 链中的顺序只需要修改 getOrder 的返回值即可,getOrder 的返回值越小在 Advisor 链中的顺序越靠前,也就是越早处理请求。
所以如果我们希望把 SGCallAdvisor2 的 getOrder 返回值设置为 1。打印的结果就变成了:

案例 - 自定义 SimpleMessageChatMemoryAdvisor
我们通过一个简化版的 MessageChatMemoryAdvisor 来学习并理解如何自定义 Advisor。
需求:我们希望能在能够进行多轮对话,模型能知道我们之前聊过什么内容。
设计思路:
1.把对话记录 (用户发送的消息和 AI 回复的消息) 存储到内存中
2.每个会话有自己的会话 id 来判断自己的消息记录是哪些
3.给模型的请求中需要携带之前的聊天记录
由于如果要同时对同步调用和流式调用都进行增强,需要同时实现 CallAdvisor 和 StreamAdvisor,而如果要增强的地方是一样的,都需要写一遍就会比较麻烦,SpringAI 还提供了一个接口 BaseAdvisor,这个接口直接继承了上述两个接口,并且把公共要增强的地方抽象成了两个方法 before 和 after,直接实现这两个方法就可以了。
BaseAdvisor 的定义:
public interface BaseAdvisor extends CallAdvisor, StreamAdvisor {
@Override
default ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
Assert.notNull(chatClientRequest, "chatClientRequest cannot be null");
Assert.notNull(callAdvisorChain, "callAdvisorChain cannot be null");
ChatClientRequest processedChatClientRequest = before(chatClientRequest, callAdvisorChain);
ChatClientResponse chatClientResponse = callAdvisorChain.nextCall(processedChatClientRequest);
return after(chatClientResponse, callAdvisorChain);
}
@Override
default Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest,
StreamAdvisorChain streamAdvisorChain) {
Assert.notNull(chatClientRequest, "chatClientRequest cannot be null");
Assert.notNull(streamAdvisorChain, "streamAdvisorChain cannot be null");
Assert.notNull(getScheduler(), "scheduler cannot be null");
Flux<ChatClientResponse> chatClientResponseFlux = Mono.just(chatClientRequest)
.publishOn(getScheduler())
.map(request -> this.before(request, streamAdvisorChain))
.flatMapMany(streamAdvisorChain::nextStream);
return chatClientResponseFlux.map(response -> {
if (AdvisorUtils.onFinishReason().test(response)) {
response = after(response, streamAdvisorChain);
}
return response;
}).onErrorResume(error -> Flux.error(new IllegalStateException("Stream processing failed", error)));
}
@Override
default String getName() {
return this.getClass().getSimpleName();
}
ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain);
ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain);
default Scheduler getScheduler() {
return DEFAULT_SCHEDULER;
}
}
实现自定义 Advisor,直接实现 BaseAdvisor 即可:
package com.sangeng.advisor;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.AdvisorChain;
import org.springframework.ai.chat.client.advisor.api.BaseAdvisor;
import org.springframework.ai.chat.messages.Message;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class SimpleMessageChatMemoryAdvisor implements BaseAdvisor {
// 本案例主要是为了学习和理解如何写Advisor所以这里选用最简单的实现。实际肯定不能这样存储消息
private static Map<String, List<Message>> chatMemory = new HashMap<>();
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {
// 从上下文中获取会话id
String conversationId = chatClientRequest.context().get("conversationId").toString();
// 获取之前的消息记录
List<Message> messages = chatMemory.get(conversationId);
if (messages == null) {
messages = new ArrayList<>();
}
messages.addAll(chatClientRequest.prompt().getInstructions());
// 把历史消息也放入请求中
ChatClientRequest processedChatClientRequest = chatClientRequest.mutate()
.prompt(chatClientRequest.prompt().mutate().messages(messages).build())
.build();
// 获取请求中的消息 保存
chatMemory.put(conversationId, messages);
return processedChatClientRequest;
}
@Override
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
// 从上下文中获取会话id
String conversationId = chatClientResponse.context().get("conversationId").toString();
// 通过会话id查询之前的对话记录
List<Message> hisMessages = chatMemory.get(conversationId);
if (hisMessages == null) {
hisMessages = new ArrayList<>();
}
// 获取response中ai的消息 添加到对话记录中
if(Objects.isNull(chatClientResponse)){
return chatClientResponse;
}
AssistantMessage assistantMessage = chatClientResponse.chatResponse()
.getResult()
.getOutput();
hisMessages.add(assistantMessage);
chatMemory.put(conversationId, hisMessages);
return chatClientResponse;
}
@Override
public int getOrder() {
return 0;
}
}
使用自定义 Advisor:
@GetMapping("/simpleChatMemory")
public String simpleChatMemory(@RequestParam(name = "msg") String msg,@RequestParam(name = "conversationId") String conversationId) {
return chatClient.prompt()
.user(msg)
// 设置会话 id 到 advisor 的上下文
.advisors(advisorSpec -> advisorSpec.param("conversationId",conversationId))
.advisors(new SimpleMessageChatMemoryAdvisor())
.call().content();
}
使用官方的 Advisor 实现对话记录存储 - 如何统一设置 advisors
//构造器注入
public ZhipuChatMemoryController(ChatClient.Builder builder) {
// 创建 MessageWindowChatMemory
MessageWindowChatMemory windowChatMemory = MessageWindowChatMemory.builder()
.build();
//创建 MessageChatMemoryAdvisor
MessageChatMemoryAdvisor chatMemoryAdvisor = MessageChatMemoryAdvisor.builder(windowChatMemory)
.build();
this.chatClient = builder
.defaultAdvisors(chatMemoryAdvisor)
.build();
}
@GetMapping("/messageChatMemoryAdvisor")
public String messageChatMemoryAdvisor(@RequestParam(name = "query") String query,
@RequestParam(name = "conversationId") String conversationId) {
return chatClient.prompt()
.user(query)
// 会话 id 存储在 key 为 ChatMemory.CONVERSATION_ID(从 MessageChatMemoryAdvisor 源码可以找到)的上下文中
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID, conversationId))
.call()
.content();
}
MessageWindowChatMemory 原理
查看 MessageWindowChatMemory 源码,可以发现它的实现机制是通过一个滑动窗口来管理聊天记忆,默认保留最近 20 条消息,超出容量时自动删除旧消息。
消息存储的地方通过 Builder 的 chatMemoryRepository 方法进行设置,需要传入一个 ChatMemoryRepository 的具体实现,如果不设置,则默认使用 InMemoryChatMemoryRepository,这个实现是将消息存储在内存中的(Map<String, List<Message>> chatMemoryStore = new ConcurrentHashMap<>();)。
Prompt Template
概述
为什么需要
例如我们需要写的提示词是这样的
你是一个有用的人工智能助手,名字是小白,请用幽默的风格回答以下问题:推荐上海的三个景点
我们希望助手的名字,风格,还需要回答的问题都是可变的。如果我们没有没有 PromptTemplate 的情况下可以需要写成这样的:
String name = "小王";
String voice = "幽默";
String userQuestion = "推荐上海的三个景点";
// 硬编码拼接提示词
String promptText = "你是一个有用的人工智能助手,名字是" + name + ",请用" + voice + "的风格回答以下问题:" + userQuestion;
这种方式存在几个明显问题:
- 代码臃肿:每次需要改变提示词结构或角色设定时,都必须修改代码并重新部署。
- 难以维护:如果提示词逻辑变得复杂(例如需要加入系统指令、上下文历史等),字符串拼接会变得非常混乱且容易出错。
- 缺乏复用性:相同的提示词结构无法轻松应用于其他类似场景。
而使用 PromptTemplate 就可以解决这些问题。
是什么
在 Spring AI 的开发过程中,Prompt Template(提示词模板) 的核心价值在于它能够将静态的提示词结构与动态的业务数据分离,从而提升代码的可维护性和复用性。当你的应用需要与大型语言模型(LLM)交互,且交互内容会根据用户输入或业务状态发生变化时,就是使用 Prompt Template 的典型场景。
如何使用
渲染用户提示词,使用 PromptTemplate:
// 创建UserMessage
PromptTemplate userPrompt = new PromptTemplate("你是一个有用的人工智能助手,名字是{name}请用{voice}的风格回答以下问题:{userQuestion}");
Message message = userPrompt.createMessage(Map.of("name", "小白", "voice", "幽默", "userQuestion", "推荐上海的三个景点"));
System.out.println(message);
渲染系统提示词,使用 SystemPromptTemplate:
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate("你是一个有用的人工智能助手,名字是{name}请用{voice}的风格回答以下问题:{userQuestion}");
Message message2 = systemPromptTemplate.createMessage(Map.of("name", "小白", "voice", "幽默", "userQuestion", "推荐上海的三个景点"));
System.out.println(message2);
RAG
概述
为什么需要 RAG
我们去问 AI 一些问题的时候,如果这个知识是模型在训练时没有涉及到的,这个时候 AI 就会出现幻觉(看似合理但实则错误或虚构的信息)。
所以我们想要避免 AI 出现幻觉就需要让 AI 知道相关的知识。
检索增强生成(RAG)技术其核心价值在于,它以一种成本效益高且灵活的方式,为 LLM 连接了一个可实时更新的“外部知识库”,从而显著提升了 AI 应用的可靠性、时效性和专业性。
什么是 RAG
RAG(Retrieval-Augmented Generation) 检索增强生成。通过外部数据库检索出相关的知识,然后把问题和相关知识一起给到大模型来让模型生成回答。
RAG 流程
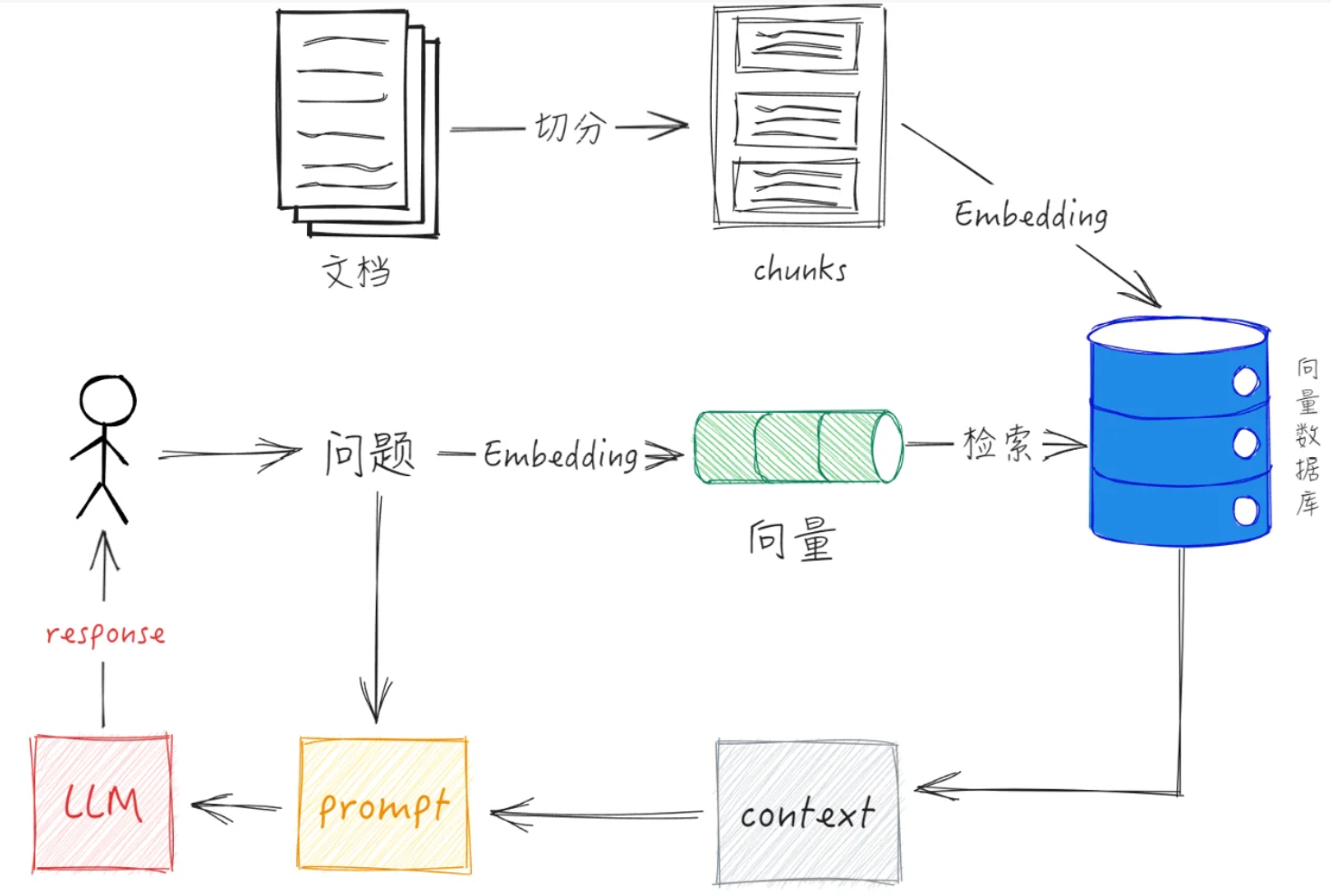
相关概念
| 向量 | 向量就像是一个有序的数字列表,或者说是多维空间中的一个点、一条有方向的线段。这些数字共同描述了对象在某一个“特征空间”中的位置。 |
|---|---|
| 为什么要把文本转换成向量 | 计算机无法直接理解人类语言,但极其擅长处理数字。一旦文本变成了向量(即高维空间中的点),我们就可以运用强大的数学工具来处理它们,计算相似度。(比如余弦相似度算法) |
| Embedding 嵌入 | 把文本 ->多维向量的过程叫做 Embedding 嵌入。 |
| EmbeddingMode 嵌入模型 | 嵌入模型可以把文本转换成多维向量 |
| 向量数据库 | 能够存储向量并且具有向量相似度检索相关能力的数据库 |
| 向量维度 | 向量的维度就是这个列表里数字的个数。例如,向量 [0.12, -0.87, 0.33, 1.24] 的维度是 4; 较高维度通常能提供更丰富的语义信息和更强的区分能力,尤其利于处理复杂语义或需要高精度的场景。但这会增加计算量,占用更多内存和存储,也可能使计算速度变慢 |
数据嵌入和相似度搜索入门案例
目标
- 使用 redis-stack 作为向量数据库。
- 提供一个接口,接口被调用的时候可以把文本向量化然后存入向量数据库
- 另外再提供一个接口,这个接口能基于问题去向量数据库的中进行相似度搜索,查询出相似度较高的几个数据。
准备工作
docker 安装 redis-stack
首先我们需要先使用 docker 部署一个 redis-stack 供我们使用
docker run -d --name redis-stack
-p 6379:6379
-p 8001:8001 redis/redis-stack:latest
添加依赖
创建好新工程后添加依赖,因为我们要使用 redis 作为向量数据库所以主要是加了个 spring-ai-starter-vector-store-redis 的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
添加配置
相比于之前的案例主要是添加了:redis 的连接信息配置,向量存储配置,和 embedding 模型向量维度的配置
# 服务器配置
server:
port: 8080 # 应用服务监听端口,默认8080
spring:
# 应用基本信息配置
application:
name: sangeng-redis-rag # 应用名称
# Spring AI 配置
ai:
# 智谱AI大模型配置
zhipuai:
api-key: ${ZHIPU_KEY} # 智谱API密钥(从环境变量ZHIPU_KEY获取)
chat:
options:
model: glm-4.6 # 使用的聊天模型名称(GLM-4.6)
embedding:
options:
model: embedding-3 # 使用的嵌入模型名称(embedding-3)
dimensions: 256 # 嵌入向量的维度(256维)
# 向量存储配置
vectorstore:
redis:
initialize-schema: true # 启动时自动创建Redis向量索引结构(首次部署需开启)
prefix: sangeng_rag_prefix # Redis键名前缀,用于区分不同应用的向量数据
index: sangeng_rag_index # Redis向量索引名称
# 数据源配置
data:
redis:
host: localhost # Redis服务器地址
port: 6379 # Redis服务器连接端口(默认6379)
创建启动类
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class RedisVectorStoreApplication {
public static void main(String[] args) {
SpringApplication.run(RedisVectorStoreApplication.class, args);
}
}
代码编写
注入 VectorStore
@RestController
@RequestMapping("/redis")
public class RedisController {
private final VectorStore vectorStore;
public RedisController(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
}
数据存储
@GetMapping("/import")
public void importData(@RequestParam(name = "content") String content) {
List<Document> documents = List.of(new Document(content));
vectorStore.add(documents);
}
相似度搜索数据
@PostMapping("/search")
public List<Document> search(@RequestParam("query") String query) {
SearchRequest searchRequest = SearchRequest.builder()
.topK(10)
.query(query)
.similarityThreshold(0.8)
.build();
List<Document> documents = vectorStore.similaritySearch(searchRequest);
return documents;
}
咖啡店智能客服 RAG 实战
目标
使用 RetrievalAugmentationAdvisor 把常见咖啡店相关的 QA 数据存入向量数据库。让用户问智能客服相关问题的时候能够回答出来。
思路
先把 csv 文件中每一个 QA 作为一个 Document 存入向量数据库
用户提问的时候先基于用户的问题去向量数据库中检索相关的知识。然后把让 AI 能够基于这些知识去回答。
代码实现
添加 csv 解析依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.10.0</version>
</dependency>
添加 RAG 依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>
package com.sangeng.controller;
import org.apache.commons.csv.CSVFormat;
import org.apache.commons.csv.CSVParser;
import org.apache.commons.csv.CSVRecord;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.ClassPathResource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
@RestController
@RequestMapping("/coffee")
public class CoffeeController {
private final VectorStore vectorStore;
private final ChatClient chatClient;
public CoffeeController(VectorStore vectorStore,ChatClient.Builder chatClientBuilder) {
this.vectorStore = vectorStore;
// 向量数据库文档检索器
VectorStoreDocumentRetriever vectorStoreDocumentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.topK(3)
.similarityThreshold(0.5)
.build();
// 检索增强器
RetrievalAugmentationAdvisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(vectorStoreDocumentRetriever)
.build();
this.chatClient = chatClientBuilder
.defaultAdvisors(retrievalAugmentationAdvisor)
.build();
}
@GetMapping("/import")
public String importCSV() {
try {
// 读取classpath下的QA.csv文件
ClassPathResource resource = new ClassPathResource("QA.csv");
InputStreamReader reader = new InputStreamReader(resource.getInputStream());
// 使用Apache Commons CSV解析CSV文件
CSVParser csvParser = CSVFormat.DEFAULT
.builder()
.setHeader() // 第一行作为标题
.setSkipHeaderRecord(true) // 跳过标题行
.build()
.parse(reader);
List<Document> documents = new ArrayList<>();
// 遍历每一行记录
for (CSVRecord record : csvParser) {
// 获取问题和回答字段
String question = record.get("问题");
String answer = record.get("回答");
// 将问题和回答组合成文档内容
String content = "问题: " + question + "\n回答: " + answer;
// 创建Document对象
Document document = new Document(content);
// 添加到文档列表
documents.add(document);
}
// 关闭解析器
csvParser.close();
// 将文档存入向量数据库
vectorStore.add(documents);
return "成功导入 " + documents.size() + " 条记录到向量数据库";
} catch (IOException e) {
e.printStackTrace();
return "导入失败: " + e.getMessage();
}
}
/**
* 新增的RAG问答接口,明确展示查询向量数据库的过程
* @param question 用户的问题
* @return AI基于检索到的信息生成的回答
*/
@GetMapping("/rag-ask")
public String ragAskQuestion(@RequestParam("question") String question) {
// 先从向量数据库中检索相关信息
// 这里会使用RetrievalAugmentationAdvisor自动检索相关文档
// 将问题和检索到的上下文一起发送给AI模型生成回答
return chatClient.prompt()
.system("你是三更咖啡的服务员,你需要回答用户的问题.")
.user(question)
.call()
.content();
}
}
RAG 增强后的提示词:
Context information is below.
---------------------
问题: 咖啡制作需要多长时间?
回答: 我们的咖啡制作时间很快:美式咖啡约1-2分钟,拿铁、卡布奇诺约2-3分钟,摩卡、焦糖玛奇朵约3-4分钟。我们使用专业意式咖啡机,确保每杯咖啡的品质和口感。高峰期可能稍有延迟,请您耐心等待。
问题: 拿铁和卡布奇诺有什么区别?
回答: 拿铁和卡布奇诺都是意式浓缩加牛奶制作。拿铁的牛奶比例更高,奶泡较薄,口感更温和顺滑,奶香浓郁;卡布奇诺的奶泡更厚更丰富,咖啡味更突出。拿铁适合喜欢奶香的客人,卡布奇诺适合想要平衡咖啡和奶味的客人。
问题: 拿铁和卡布奇诺有什么不同?
回答: 拿铁和卡布奇诺都是意式浓缩加牛奶制作。拿铁的牛奶比例更高,奶泡较薄,口感更温和顺滑;卡布奇诺的奶泡更厚,咖啡味更浓郁。拿铁适合喜欢奶香的客人,卡布奇诺适合想要平衡咖啡和奶味的客人。
---------------------
Given the context information and no prior knowledge, answer the query.
Follow these rules:
1. If the answer is not in the context, just say that you don't know.
2. Avoid statements like "Based on the context..." or "The provided information...".
Query: 拿铁需要做多久啊
Answer:
Tool Calling
概述
为什么需要 Tool Calling
如果我们现在问我们前面的智能客服说:我现在下单一杯美式几点几分可以做好
你会发现他没办法很好的回答问题。因为模型能力是有限的 (比如不知道当前时间),如果想要让 AI 应用具备更强的功能,就可以使用 tool calling。相当于是给模型提供一些工具,当模型判断需要使用工具的时候就会进行使用。
tool calling 调用流程
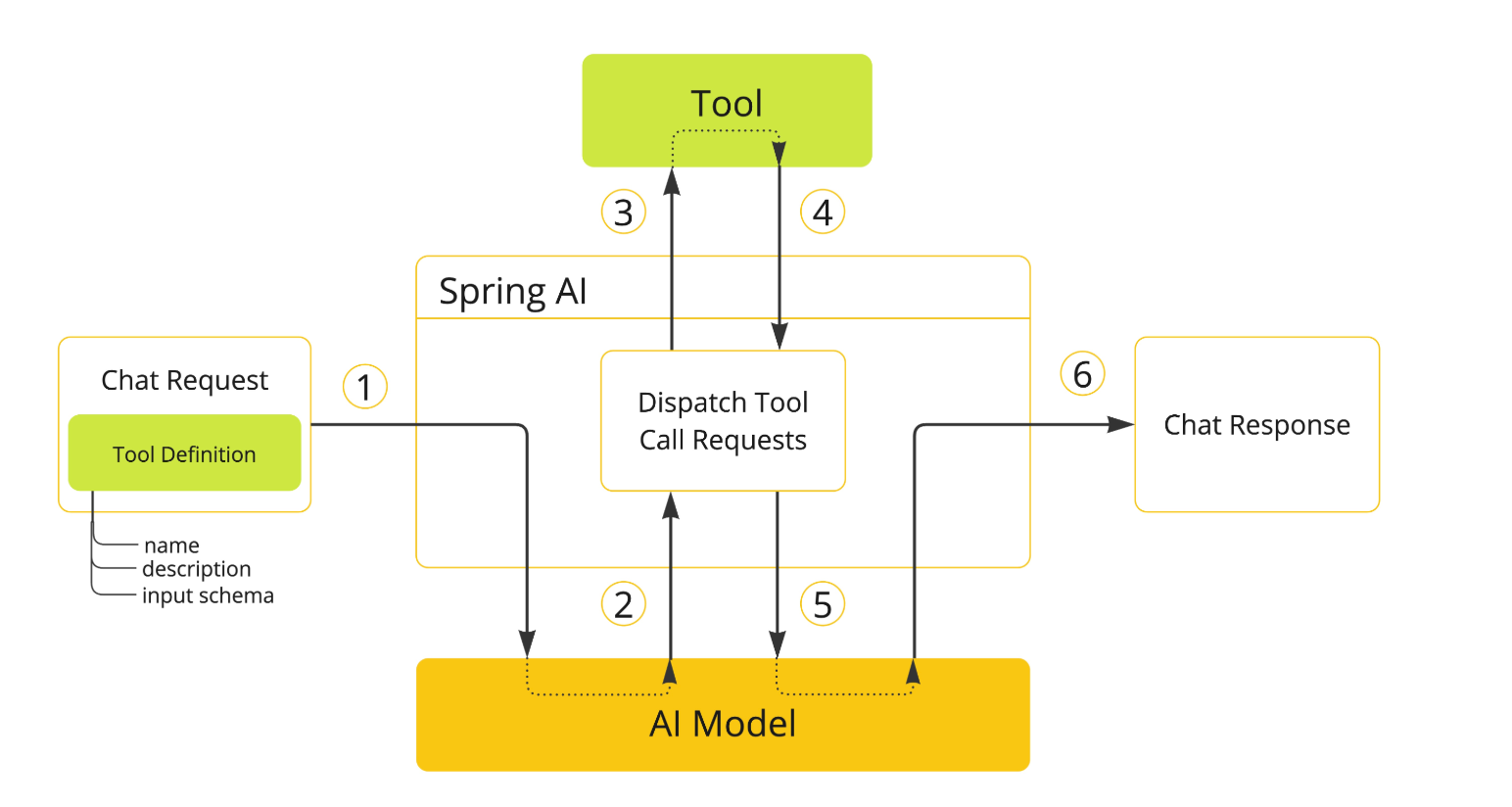
其实就是把工具的 name,description,input schema 等信息也放入模型的请求中。
模型如果觉得需要调用工具就会返回相关的工具调用消息,这个时候 SpringAI 会基于这个消息去调用工具,得到一个工具调用的结果给到模型。
模型再综合这个调用结果返回最终的答案。
案例
定义工具
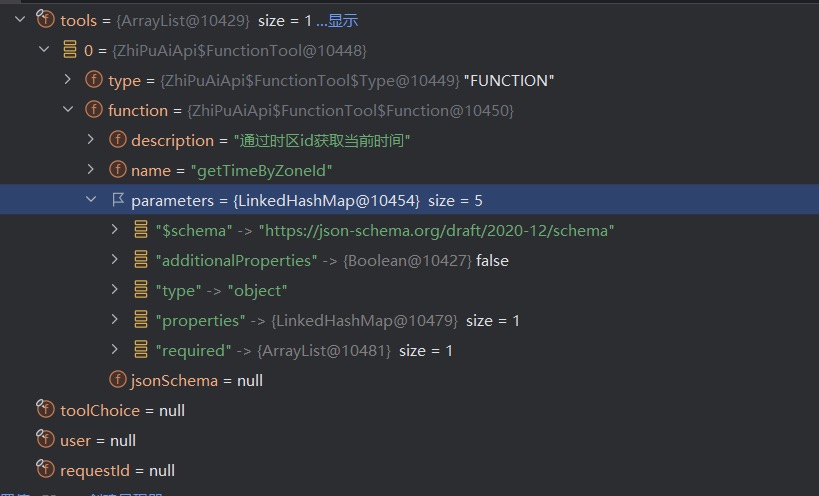
public class TimeTools {
@Tool(description = "通过时区id获取当前时间")
public String getTimeByZoneId(@ToolParam(description = "时区id, 比如 Asia/Shanghai")
String zoneId) {
ZoneId zid = ZoneId.of(zoneId);
ZonedDateTime zonedDateTime = ZonedDateTime.now(zid);
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss z");
return zonedDateTime.format(formatter);
}
}
传入工具
@GetMapping("/ask")
public String askQuestion(@RequestParam("question") String question) {
return chatClient.prompt()
.user(question)
.tools(new TimeTools())
.call()
.content();
}
底层调用探究
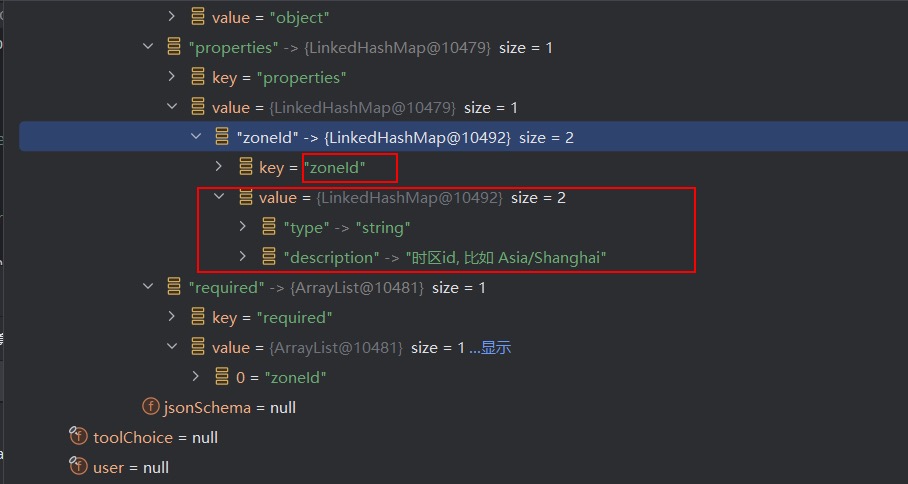
SpringAI 在底层通过 HTTP 请求调用模型时,请求体中携带了 tools 的相关信息:
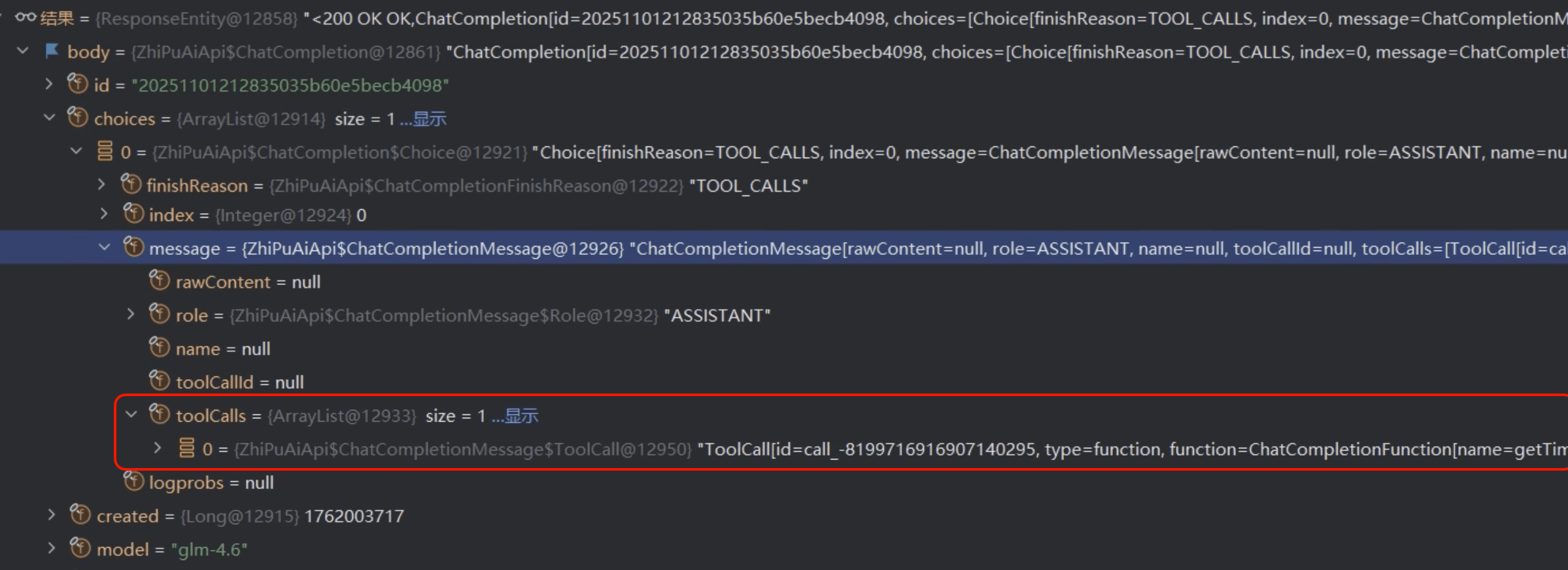
第一次请求的返回结果中,toolCalls 中的内容就是模型想要调用的工具以及调用工具需要的参数信息:
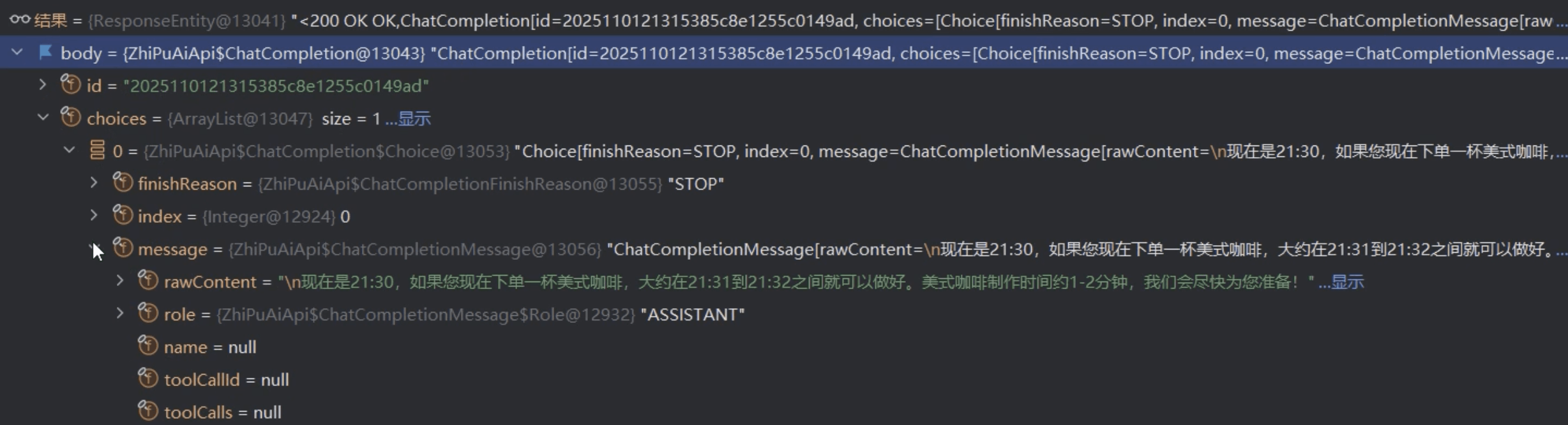
SpringAI 获得模型想要调用的工具信息后,帮助模型调用工具,之后再次调用模型,此时调用模型的请求体中,messages 中就包含了工具调用的结果:

第二次调用模型后,模型返回最终结果:
MCP
概述
为什么需要 MCP
在 MCP 出现之前,AI 应用开发面临一个显著的效率瓶颈,常被称为“M×N”问题。这意味着,如果有 M 个不同的大模型(如 GPT、Claude、文心一言等)需要与 N 种外部工具或数据源(如数据库、API、文件系统)进行交互,开发者就需要为每一种组合(M 乘以 N)编写特定的、通常不可复用的适配代码
这种点对点的集成方式导致了:
- 高昂的重复开发成本:每个新工具或新模型的引入都意味着大量的重复集成工作。
- 生态系统碎片化:不同厂商的模型有不同的函数调用接口和规范,使得为一个模型开发的工具很难被其他模型直接使用。
- 复杂的维护负担:当某个工具或模型的 API 发生变更时,所有与之相关的集成点都需要同步更新,维护成本非常高
什么是 MCP
MCP(Model Context Protocol,模型上下文协议)是 Anthropic 公司推出的开放协议,旨在标准化大语言模型与外部工具、数据源的交互方式。
官方文档:https://modelcontextprotocol.io/docs/learn/architecture
MCP 相关概念
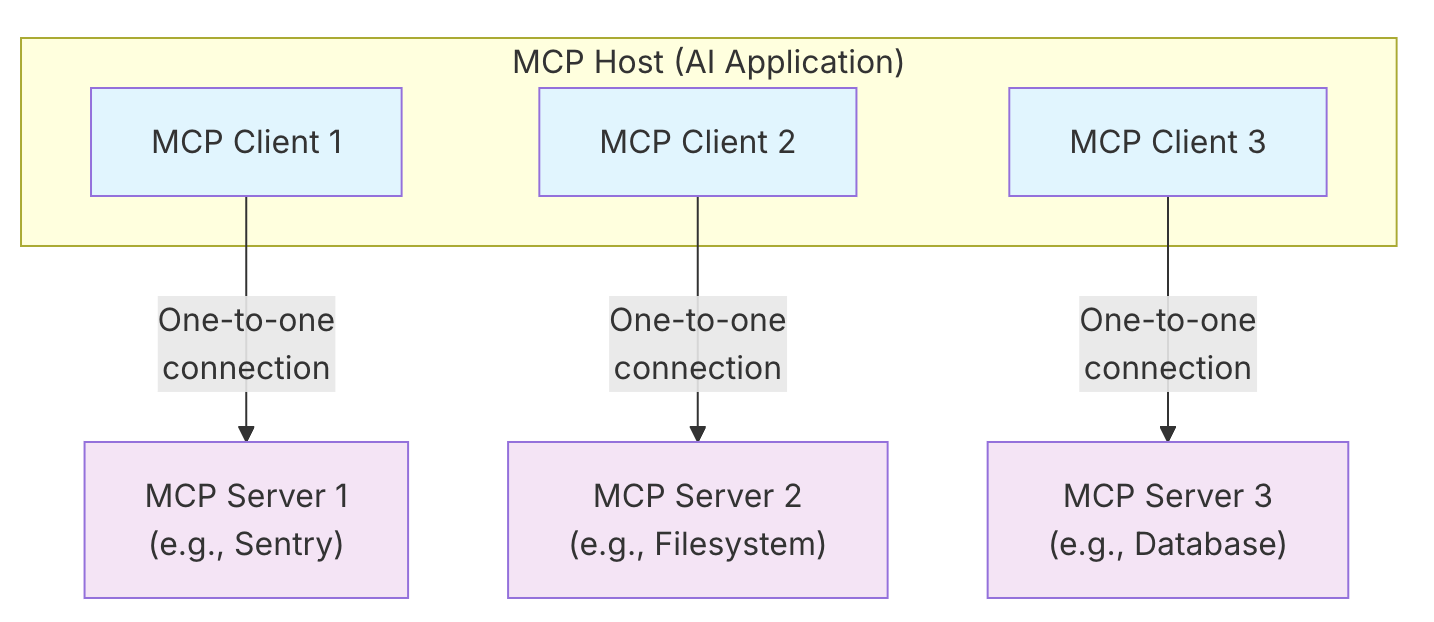
| MCP host -MCP 主机 | 使用 mcp 协议调用工具的应用程序。例如 claude code,或者我们自己写的 spring ai 应用等。它负责协调和管理一个或多个 MCP 客户端的 AI 应用程序。MCP 主机通过为每个 MCP 服务器创建一个 MCP 客户端来实现连接。 |
|---|---|
| MCP client - MCP 客户端 | 与 MCP 服务器保持连接并从 MCP 服务器获取上下文,供 MCP 主机使用的组件 |
| MCP server MCP 服务端 | 给 AI 模型提供工具的服务 |
入门案例
目标
创建一个 MCP Server 去提供一个工具
工具方法如下:
public String getTimeByZoneId(String zoneId) {
ZoneId zid = ZoneId.of(zoneId);
ZonedDateTime zonedDateTime = ZonedDateTime.now(zid);
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss z");
return zonedDateTime.format(formatter);
}
然后使用 MCP Client 去获取这个 MCP Server 上的工具来提供给模型
创建 MCP 服务端
创建新工程后添加依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
创建启动类
package com.sangeng;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class McpServerApplication {
public static void main(String[] args) {
SpringApplication.run(McpServerApplication.class, args);
}
}
定义工具:
package com.sangeng.tool;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Component;
import java.time.ZoneId;
import java.time.ZonedDateTime;
import java.time.format.DateTimeFormatter;
@Component
public class TimeTools {
@Tool(description = "通过时区id获取当前时间")
public String getTimeByZoneId(@ToolParam(description = "时区id, 比如 Asia/Shanghai")
String zoneId) {
ZoneId zid = ZoneId.of(zoneId);
ZonedDateTime zonedDateTime = ZonedDateTime.now(zid);
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss z");
return zonedDateTime.format(formatter);
}
}
配置工具对外提供
@Configuration
public class McpConfig {
@Bean
public ToolCallbackProvider weatherTools(TimeTools tools) {
return MethodToolCallbackProvider.builder().toolObjects(tools).build();
}
}
创建 MCP 客户端
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
主要是增加了 mcp 服务的配置
spring:
ai:
zhipuai:
api-key: ${ZHIPU_KEY} # 配置 API Key
chat:
options:
model: glm-4.5
mcp:
client:
sse:
connections:
server1:
url: http://localhost:8080 # mcp服务url
http:
client:
read-timeout: 100000
server:
port: 8888
配置工具信息到 chatClient:
public CoffeeController(VectorStore vectorStore, ChatClient.Builder chatClientBuilder, ToolCallbackProvider toolCallbackProvider) {
this.vectorStore = vectorStore;
VectorStoreDocumentRetriever vectorStoreDocumentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.topK(3)
.similarityThreshold(0.5)
.build();
RetrievalAugmentationAdvisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(vectorStoreDocumentRetriever)
.build();
this.chatClient = chatClientBuilder
.defaultAdvisors(retrievalAugmentationAdvisor)
.defaultToolCallbacks(toolCallbackProvider.getToolCallbacks())
.build();
}
网页信息爬取 MCP
https://www.mcpworld.com/zh/detail/fc9b5b85dcb2d8dad2a18c5f2cffc7e1
Docker 部署 MCP
创建 docker-compose.yml 内容如下:
version: "3.8"
services:
fetcher-mcp:
image: ghcr.io/jae-jae/fetcher-mcp:latest
container_name: fetcher-mcp
restart: unless-stopped
ports:
- "3000:3000"
environment:
- NODE_ENV=production
# Using host network mode on Linux hosts can improve browser access efficiency
# network_mode: "host"
volumes:
# For Playwright, may need to share certain system paths
- /tmp:/tmp
# Health check
healthcheck:
test: ["CMD", "wget", "--spider", "-q", "http://localhost:3000"]
interval: 30s
timeout: 10s
retries: 3
使用 docker-compose up -d 启动
添加 MCP 服务端相关配置
spring:
ai:
# 智谱AI大模型配置
zhipuai:
api-key: ${ZHIPU_KEY} # 智谱API密钥(从环境变量ZHIPU_KEY获取)
chat:
options:
model: glm-4.6 # 使用的聊天模型名称(GLM-4.6)
embedding:
options:
model: embedding-3 # 使用的嵌入模型名称(embedding-3)
dimensions: 256 # 嵌入向量的维度(256维)
mcp:
client:
sse:
connections:
server1:
url: http://localhost:8080 # mcp服务url
fetcher-mcp:
url: http://localhost:3000
@GetMapping("/fetcher")
public String fetcher(@RequestParam("question") String question) {
return chatClient.prompt()
.system("你是一个网页爬取专家,你可以运用工具爬取指定网页的内容并且进行总结")
.user(question)
.call().content();
}
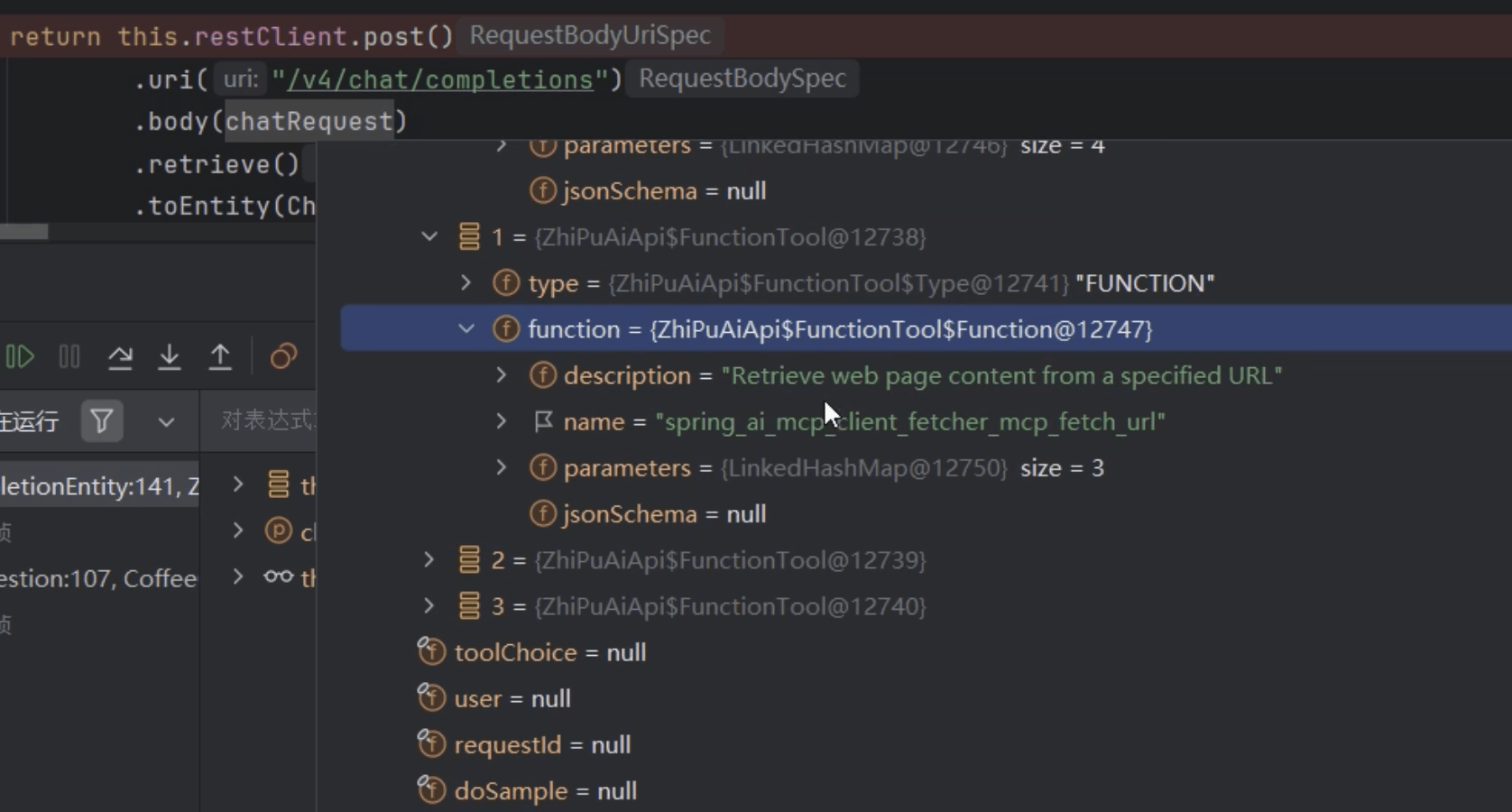
可以看到实际在请求模型时,请求体中携带了多个 tools (一个 mcp 服务可以提供多个 tools):
Graph
概述
为什么需要 Graph
假设你需要处理一个真实的商业需求:比如自动化审核一份商业合同。
拆分:
- 理解内容:先请 AI 通读合同,提炼摘要和关键条款。
- 合规检查:再让 AI 根据公司政策库,判断合同是否有合规风险。
- 风险评估:接着,要求 AI 从法律、财务等多维度给出风险评分。
- 人工介入:最后,必须将 AI 的分析结果提交给法务专家,由专家做出“批准”、“拒绝”或“要求修改”的最终决定。
- 后续动作:系统根据专家的决策,自动进入不同的处理流程(如生成公文、起草拒绝函等)。
你会发现它变成了一个多步骤、有状态、且需要协调 AI 自动化和人类决策的复杂流程。这就是我们常说的 AI 工作流(AI Workflow)或智能体(AI Agent) 要处理的核心问题。
在没有 Graph 之前,实现这样的流程会非常麻烦,需要我们写很多硬编码去编排实现。
而 Spring AI Alibaba Graph 就是为了优雅地解决这些问题而生的。它是一个强大的工作流编排引擎,让你能像画流程图一样,直观地定义和执行复杂的 AI 应用流程
核心概念
| State (状态) | 负责在不同步骤间安全地传递和共享数据的容器 |
|---|---|
| Node (节点) | 代表一个执行单元,可以是一个 AI 调用、一个数据库操作,或一段业务逻辑 |
| Edge (边) | 定义节点之间的连接关系和流转方向。可以是固定的简单边,也可以是能根据 State 内容决定下一步的条件边。 |
快速入门
准备工作
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-graph-core</artifactId>
</dependency>
创建配置文件
# 服务器配置
server:
port: 8889 # 应用服务监听端口,默认8889
spring:
# 应用基本信息配置
application:
name: sangeng-graph # 应用名称
# Spring AI 配置
ai:
# 智谱AI大模型配置
zhipuai:
api-key: ${ZHIPU_KEY} # 智谱API密钥(从环境变量ZHIPU_KEY获取)
chat:
options:
model: glm-4.6 # 使用的聊天模型名称(GLM-4.6)
创建启动类
@SpringBootApplication
public class GraphApplication {
public static void main(String[] args) {
SpringApplication.run(GraphApplication.class, args);
}
}
代码编写
定义状态图 (状态,节点,边),编译生成 CompiledGraph 后注入 Spring 容器
@Configuration
public class GraphConfiguration {
private static final Logger log = LoggerFactory.getLogger(GraphConfiguration.class);
@Bean("quickStartGraph")
public CompiledGraph quickStartGraph() throws GraphStateException {
KeyStrategyFactory keyStrategyFactory = new KeyStrategyFactory() {
@Override
public Map<String, KeyStrategy> apply() {
return Map.of("input1",new ReplaceStrategy()
,"input2",new ReplaceStrategy());
}
};
// 定义状态
StateGraph stateGraph = new StateGraph("quickStartGraph", keyStrategyFactory);
//定义节点
stateGraph.addNode("node1", AsyncNodeAction.node_async(new NodeAction() {
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
log.info("node1 state :{}", state);
return Map.of("input1",1,
"input2",1);
}
}));
stateGraph.addNode("node2", AsyncNodeAction.node_async(new NodeAction() {
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
log.info("node2 state :{}", state);
return Map.of("input1",2,
"input2",2);
}
}));
//定义边
stateGraph.addEdge(StateGraph.START,"node1");
stateGraph.addEdge("node1","node2");
stateGraph.addEdge("node2",StateGraph.END);
// 编译状态图
return stateGraph.compile();
}
}
需要调用图的时候使用 CompiledGraph 的 call 方法调用
@RestController
@RequestMapping("/graph")
public class GraphController {
private final CompiledGraph compiledGraph;
public GraphController(CompiledGraph compiledGraph) {
this.graph = graph;
}
@GetMapping("/quickStartGraph")
public String quickStartGraph(){
Optional<OverAllState> overAllStateOptional = compiledGraph.call(Map.of());
log.info("overAllStateOptional: {}", overAllStateOptional);
return "ok";
}
}
API 详解
KeyStrategyFactory
用来定义图中的状态有哪些数据,并且定义这些数据的更新策略是什么。
有三种策略分别是:替换(ReplaceStrategy),合并(MergeStrategy),追加(AppendStrategy)
KeyStrategyFactory keyStrategyFactory = () -> {
HashMap<String, KeyStrategy> keyStrategyHashMap = new HashMap<>();
keyStrategyHashMap.put("input1", new ReplaceStrategy());
keyStrategyHashMap.put("input2", new MergeStrategy());
keyStrategyHashMap.put("input3", new AppendStrategy());
return keyStrategyHashMap;
};
替换(ReplaceStrategy): 新值替换掉老值
合并(MergeStrategy):适合 Map 类型的数据,新老 Map 的数据和合并
追加(AppendStrategy):适合 List 类型的数据,新 List 的数据追加到老 List 中
AsyncNodeAction&NodeAction
NodeAction 是 Graph 中对节点的抽象。我们只需要实现 NodeAction 接口,在 apply 方法中定义节点的执行逻辑即可。
@FunctionalInterface
public interface NodeAction {
Map<String, Object> apply(OverAllState state) throws Exception;
}
AsyncNodeAction 是异步节点,提供了一个静态方法可以 NodeAction 转化成 AsyncNodeAction
@FunctionalInterface
public interface AsyncNodeAction extends Function<OverAllState, CompletableFuture<Map<String, Object>>> {
/**
* Applies this action to the given agent state.
* @param state the agent state
* @return a CompletableFuture representing the result of the action
*/
CompletableFuture<Map<String, Object>> apply(OverAllState state);
/**
* Creates an asynchronous node action from a synchronous node action.
* @param syncAction the synchronous node action
* @return an asynchronous node action
*/
static AsyncNodeAction node_async(NodeAction syncAction) {
return state -> {
Context context = Context.current();
CompletableFuture<Map<String, Object>> result = new CompletableFuture<>();
try {
result.complete(syncAction.apply(state));
}
catch (Exception e) {
result.completeExceptionally(e);
}
return result;
};
}
}
StateGraph
状态图的抽象,需要配置状态 (通过 KeyStrategyFactory ),节点,边。
配置好后通过 compile 方法编译成 CompiledGraph 后才可以供调用。
@Bean("quickStartGraph")
public CompiledGraph quickStartGraph() throws GraphStateException {
KeyStrategyFactory keyStrategyFactory = new KeyStrategyFactory() {
@Override
public Map<String, KeyStrategy> apply() {
return Map.of("input1",new ReplaceStrategy()
,"input2",new ReplaceStrategy());
}
};
// 定义状态图 StateGraph
StateGraph stateGraph = new StateGraph("quickStartGraph", keyStrategyFactory);
//定义节点
stateGraph.addNode("node1", AsyncNodeAction.node_async(new NodeAction() {
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
log.info("node1 state :{}", state);
return Map.of("input1",1,
"input2",1);
}
}));
stateGraph.addNode("node2", AsyncNodeAction.node_async(new NodeAction() {
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
log.info("node2 state :{}", state);
return Map.of("input1",2,
"input2",2);
}
}));
//定义边
stateGraph.addEdge(StateGraph.START,"node1");
stateGraph.addEdge("node1","node2");
stateGraph.addEdge("node2",StateGraph.END);
// 编译状态图
return stateGraph.compile();
}
CompiledGraph
CompiledGraph 是 StateGraph 编译后的结果,CompiledGraph 才能用了执行。
一般我们是把 StateGraph 定义好后调用其 compile 方法得到一个 CompiledGraph 放入 Spring 容器中。
然后在需要的时候从容器中注入然后再调用。
例如:
@RestController
@RequestMapping("/graph")
public class GraphController {
private static final Logger log = LoggerFactory.getLogger(GraphController.class);
private final CompiledGraph compiledGraph;
public GraphController(CompiledGraph compiledGraph) {
this.compiledGraph = compiledGraph;
}
@GetMapping("/quickStartGraph")
public String quickStartGraph(){
Optional<OverAllState> overAllStateOptional = compiledGraph.call(Map.of());
log.info("overAllStateOptional: {}", overAllStateOptional);
return "ok";
}
案例
需求
使用 Graph 去开发一个英语学习小助手。功能如下:输入一个单词,能基于这个单词造句,然后再对句子进行翻译,把造句的译文也返回。
思路分析
我们可以定义一个工作流,工作流中主要有两个节点:
SentenceConstructionNode 造句节点,拿输入的单词让 LLM 进行造句。
TranslationNode 翻译节点,能够把一个英文句子翻译成中文。
最终把造句的结果和翻译的结果返回即可。
代码实现
定义 SentenceConstructionNode 节点
/**
* 句子构造节点
*
* 该节点负责根据用户输入的单词生成包含该单词的英文句子
* 实现了NodeAction接口,作为Graph工作流中的一个处理节点
*/
public class SentenceConstructionNode implements NodeAction {
// AI聊天客户端,用于与AI模型交互
private final ChatClient chatClient;
/**
* 构造函数
*
* @param builder ChatClient构建器,用于创建聊天客户端实例
*/
public SentenceConstructionNode(ChatClient.Builder builder) {
// 构建ChatClient实例
this.chatClient = builder.build();
}
/**
* 节点执行逻辑
*
* 从状态中获取用户输入的单词,使用AI模型生成包含该单词的英文句子
*
* @param state 工作流状态对象,包含当前工作流的所有数据
* @return 包含生成句子的Map,将被合并到工作流状态中
* @throws Exception 执行异常
*/
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 从状态中获取用户输入的单词,如果没有则使用空字符串
String word = state.value("word", "");
// 创建提示模板,定义AI任务
PromptTemplate promptTemplate = new PromptTemplate("你是一个英语造句专家,能够基于给定的单词进行造句。" +
"要求只返回最终造好的句子,不要返回其他信息。 给定的单词:{word}");
// 为模板添加参数
promptTemplate.add("word", word);
// 执行AI调用并获取结果
String result = this.chatClient.prompt().user(promptTemplate.render()).call().content();
// 返回结果,将被合并到工作流状态中
return Map.of("sentence", result);
}
}
定义 TranslationNode 节点
/**
* 翻译节点
*
* 该节点负责将英文句子翻译成中文
* 实现了NodeAction接口,作为Graph工作流中的一个处理节点
*/
public class TranslationNode implements NodeAction {
// AI聊天客户端,用于与AI模型交互
private final ChatClient chatClient;
/**
* 构造函数
*
* @param builder ChatClient构建器,用于创建聊天客户端实例
*/
public TranslationNode(ChatClient.Builder builder) {
// 构建ChatClient实例
this.chatClient = builder.build();
}
/**
* 节点执行逻辑
*
* 从状态中获取英文句子,使用AI模型将其翻译成中文
*
* @param state 工作流状态对象,包含当前工作流的所有数据
* @return 包含翻译结果的Map,将被合并到工作流状态中
* @throws Exception 执行异常
*/
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 从状态中获取英文句子,如果没有则使用空字符串
String sentence = state.value("sentence", "");
// 创建提示模板,定义AI翻译任务
PromptTemplate promptTemplate = new PromptTemplate("你是一个英语翻译专家,能够对句子进行翻译。要求只返回翻译的结果不要返回其他信息。要翻译的句子:{sentence}");
// 为模板添加参数
promptTemplate.add("sentence", sentence);
// 执行AI调用并获取翻译结果
String result = this.chatClient.prompt().user(promptTemplate.render()).call().content();
// 返回翻译结果,将被合并到工作流状态中
return Map.of("translation", result);
}
}
定义图
@Bean("simpleGraph")
public CompiledGraph simpleGraph(ChatClient.Builder chatClientBuilder) throws GraphStateException {
// 定义状态更新策略工厂
KeyStrategyFactory keyStrategyFactory = () -> {
HashMap<String, KeyStrategy> keyStrategyHashMap = new HashMap<>();
// 用户输入的单词,使用替换策略更新状态
keyStrategyHashMap.put("word", new ReplaceStrategy());
// 生成的句子,使用替换策略更新状态
keyStrategyHashMap.put("sentence", new ReplaceStrategy());
// 翻译结果,使用替换策略更新状态
keyStrategyHashMap.put("translation", new ReplaceStrategy());
return keyStrategyHashMap;
};
// 构建Graph工作流
StateGraph stateGraph = new StateGraph(keyStrategyFactory)
// 添加造句节点,使用异步方式执行
.addNode("sentence_construction", node_async(new SentenceConstructionNode(chatClientBuilder)))
// 添加从开始节点到造句节点的边
.addEdge(StateGraph.START, "sentence_construction")
// 添加翻译节点,使用异步方式执行
.addNode("translation", node_async(new TranslationNode(chatClientBuilder)))
// 添加从造句节点到翻译节点的边
.addEdge("sentence_construction", "translation")
// 添加从翻译节点到结束节点的边
.addEdge("translation", StateGraph.END);
return stateGraph.compile();
}
接口中调用图
@GetMapping("/invoke")
public Map<String, Object> invoke(@RequestParam(name = "word") String word) throws GraphRunnerException {
// 执行工作流,传入初始状态(包含用户输入的单词)
Optional<OverAllState> overAllStateOptional = this.compiledGraph.call(Map.of("word", word));
// 返回执行结果,如果执行失败则返回空Map
return overAllStateOptional.map(OverAllState::data).orElse(Map.of());
}
条件边
我们在定义工作流或者是 Agent 的时候我们需要基于不同的条件走不同的执行流程,这个时候我们就需要使用条件边。
例如:
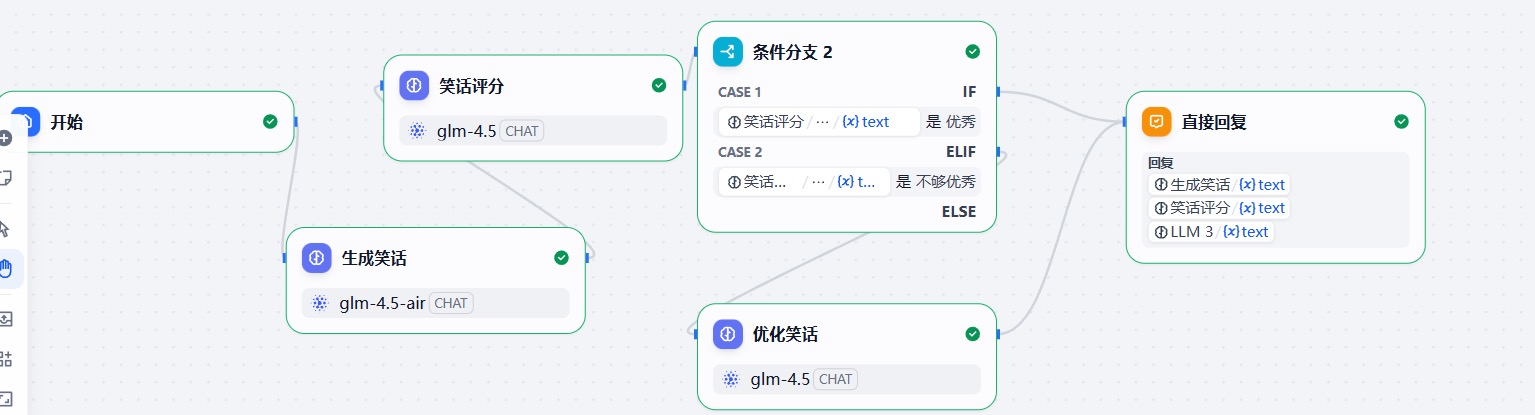
我们希望模型帮我们生成笑话,然后去评估笑话的质量,如果足够优秀就可以直接结束了。但是如果不够优秀就需要再次优化笑话。
这种情况下就是判断笑话是否优秀来走不同的执行流程。
在 Graph 中我们使用 addConditionalEdges 来定义条件边。
public StateGraph addConditionalEdges(String sourceId, AsyncEdgeAction condition, Map<String, String> mappings)
throws GraphStateException {
return addConditionalEdges(sourceId, AsyncCommandAction.of(condition), mappings);
}
其中三个参数分别代表:边的起始节点的 id,指定用来判断的数据是什么,不同的值对应不同目标节点 id 的映射关系。
接下去我们使用条件边来实现上面生成笑话的案例。
准备工作
生成笑话节点
package com.sangeng.node;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.action.NodeAction;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.prompt.PromptTemplate;
import java.util.Map;
public class GenerateJokeNode implements NodeAction {
private final ChatClient chatClient;
public GenerateJokeNode(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
String topic = state.value("topic", "");
PromptTemplate promptTemplate = new PromptTemplate("你需要写一个关于指定主题的短笑话。要求返回的结果中只能包含笑话的内容" +
"主题:{topic}");
promptTemplate.add("topic",topic);
String prompt = promptTemplate.render();
// 模型调用
String content = chatClient.prompt()
.user(prompt)
.call()
.content();
return Map.of("joke",content);
}
}
评估笑话节点
package com.sangeng.node;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.action.NodeAction;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.prompt.PromptTemplate;
import java.util.Map;
public class EvaluateJokesNode implements NodeAction {
private final ChatClient chatClient;
public EvaluateJokesNode(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 从state 中获取
String joke = state.value("joke", "");
PromptTemplate promptTemplate = new PromptTemplate("你是一个笑话评分专家,能够对笑话进行评分,基于效果的搞笑程度给出0到10分的打分。然后基于评分结果进行评价。如果大于等于3分评价:优秀 否则评价:不够优秀\n" +
"要求结果只返回最后的评价,不要其他内容。" +
"要评分的笑话::{joke}");
promptTemplate.add("joke",joke);
String prompt = promptTemplate.render();
// 模型调用
String content = chatClient.prompt()
.user(prompt)
.call()
.content();
// 把翻译结果 存入 state
return Map.of("result",content.trim());
}
}
优化笑话节点
package com.sangeng.node;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.action.NodeAction;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.prompt.PromptTemplate;
import java.util.Map;
public class EnhancejokeQualityNode implements NodeAction {
private final ChatClient chatClient;
public EnhancejokeQualityNode(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 从state 中获取
String joke = state.value("joke", "");
PromptTemplate promptTemplate = new PromptTemplate("你是一个笑话优化专家,你能够优化笑话,让它更加搞笑" +
"要优化的笑话:{joke}");
promptTemplate.add("joke",joke);
String prompt = promptTemplate.render();
// 模型调用
String content = chatClient.prompt()
.user(prompt)
.call()
.content();
// 把翻译结果 存入 state
return Map.of("newJoke",content);
}
}
定义图
@Bean("conditionalGraph")
public CompiledGraph conditionalGraph(ChatClient.Builder clientBuilder) throws GraphStateException{
KeyStrategyFactory keyStrategyFactory = () -> Map.of("topic",new ReplaceStrategy());
// 定义状态图 StateGraph
StateGraph stateGraph = new StateGraph("conditionalGraph", keyStrategyFactory);
stateGraph.addNode("生成笑话",AsyncNodeAction.node_async(new GenerateJokeNode(clientBuilder)));
stateGraph.addNode("评估笑话",AsyncNodeAction.node_async(new EvaluateJokesNode(clientBuilder)));
stateGraph.addNode("优化笑话",AsyncNodeAction.node_async(new EnhancejokeQualityNode(clientBuilder)));
stateGraph.addEdge(StateGraph.START,"生成笑话");
stateGraph.addEdge("生成笑话","评估笑话");
stateGraph.addConditionalEdges("评估笑话",AsyncEdgeAction.edge_async(
state -> state.value("result","优秀")),
Map.of("优秀",StateGraph.END,
"不够优秀","优化笑话"));
stateGraph.addEdge("优化笑话",StateGraph.END);
return stateGraph.compile();
}
循环执行
有的时候我们需要循环执行一段流程直到符合我们的要求,这就需要构建循环的结构。
例如:
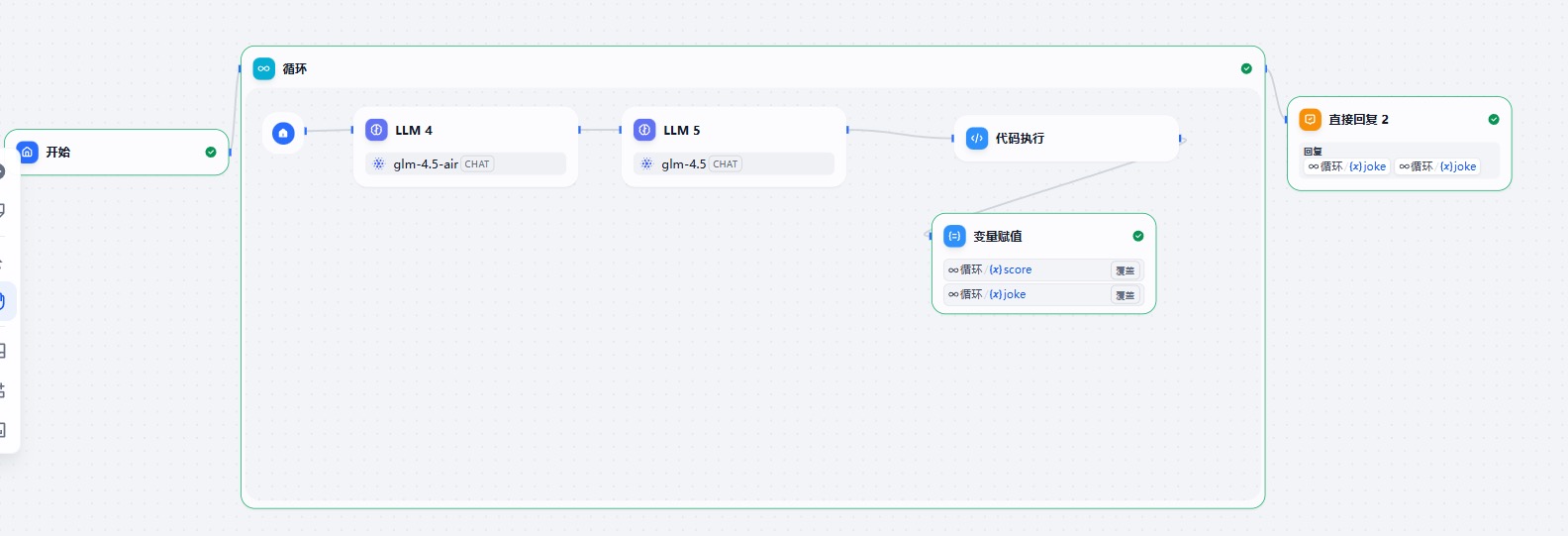
我们在 Graph 中其实就结合条件边来实现这种循环结构。
代码实现
定义评分节点
package com.sangeng.node;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.action.NodeAction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.prompt.PromptTemplate;
import java.util.Map;
public class LoopEvaluateJokesNode implements NodeAction {
private static final Logger log = LoggerFactory.getLogger(LoopEvaluateJokesNode.class);
private final ChatClient chatClient;
private final Integer targetScore ;
private final Integer maxLoopCount ;
public LoopEvaluateJokesNode(ChatClient.Builder builder, Integer targetScore, Integer maxLoopCount) {
this.chatClient = builder.build();
this.targetScore = targetScore;
this.maxLoopCount = maxLoopCount;
}
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 从state 中获取
String joke = state.value("joke", "");
Integer loopCount = state.value("loopCount", 1);
PromptTemplate promptTemplate = new PromptTemplate("你是一个笑话评分专家,能够对笑话进行评分,基于效果的搞笑程度给出0到10分的打分。要求打分只能是整数\n" +
"要求结果只返回最后的打分,不要其他内容。" +
"要评分的笑话::{joke}");
promptTemplate.add("joke",joke);
String prompt = promptTemplate.render();
// 模型调用
String content = chatClient.prompt()
.user(prompt)
.call()
.content();
// content 转化成 整数
Integer score = Integer.valueOf(content.trim());
log.info("joke {} ,score {} ,loopCount {}", joke, score,loopCount);
// 根据分数判断要继续循环还是结束 循环最多执行10次
String result = "loop";
if(score>=targetScore||loopCount>=maxLoopCount){
result = "break";
}
loopCount++;
// 把翻译结果 存入 state
return Map.of("result",result,"loopCount",loopCount);
}
}
定义图
@Bean("loopGraph")
public CompiledGraph loopGraph(ChatClient.Builder clientBuilder) throws GraphStateException{
KeyStrategyFactory keyStrategyFactory = () -> Map.of("topic",new ReplaceStrategy());
// 定义状态图 StateGraph
StateGraph stateGraph = new StateGraph("loopGraph", keyStrategyFactory);
stateGraph.addNode("生成笑话",AsyncNodeAction.node_async(new GenerateJokeNode(clientBuilder)));
stateGraph.addNode("评估笑话",AsyncNodeAction.node_async(new LoopEvaluateJokesNode(clientBuilder,7,3)));
// 定义边
stateGraph.addEdge(StateGraph.START,"生成笑话");
stateGraph.addEdge("生成笑话","评估笑话");
stateGraph.addConditionalEdges("评估笑话",AsyncEdgeAction.edge_async(new EdgeAction() {
@Override
public String apply(OverAllState state) throws Exception {
return state.value("result","loop");
}
}),Map.of("loop","生成笑话","break",StateGraph.END));
return stateGraph.compile();
}
状态存储与数据隔离
默契情况下 Graph 会把状态存储到内存中, 并且没有进行会话隔离:
@Bean("saveGraph")
public CompiledGraph saveGraph(ChatClient.Builder clientBuilder) throws GraphStateException{
KeyStrategyFactory keyStrategyFactory = () -> Map.of();
// 定义状态图
StateGraph stateGraph = new StateGraph("loopGraph", keyStrategyFactory);
stateGraph.addNode("对话存储", AsyncNodeAction.node_async(new NodeAction() {
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
String msg = state.value("msg","");
ArrayList<Object> historyMsg = state.value("historyMsg", new ArrayList<>());
historyMsg.add(msg);
return Map.of("historyMsg",historyMsg);
}
}));
// 定义边
stateGraph.addEdge(StateGraph.START,"对话存储");
stateGraph.addEdge("对话存储",StateGraph.END);
return stateGraph.compile();
}
@GetMapping("/saveGraph")
public Map<String, Object> saveGraph(@RequestParam("msg") String msg){
Optional<OverAllState> overAllStateOptional = saveGraph.call(Map.of("msg", msg));
Map<String, Object> data = overAllStateOptional.map(OverAllState::data).orElse(Map.of());
return data;
}
这个代码多次调用会发现 historyMsg 的数据在不断追加。但是我们很多时候是希望数据和数据之间是有隔离的。比如 A 会话的 ID 只能获取并且更新自己的状态数据。
我们可以在调用 call 方法的时候存入 RunnableConfig,在 RunnableConfig 中配置 threadId。
例如:
@GetMapping("/saveGraph")
public Map<String, Object> saveGraph(@RequestParam("msg") String msg,
@RequestParam("conversationID") String conversationID) {
RunnableConfig runnableConfig = RunnableConfig.builder()
.threadId(conversationID)
.build();
Optional<OverAllState> overAllStateOptional = saveGraph.call(Map.of("msg", msg), runnableConfig);
Map<String, Object> data = overAllStateOptional.map(OverAllState::data).orElse(Map.of());
return data;
}
这样就会根据会话 ID 进行数据隔离。
查看 StateGraph.compile() 方法的源码:
public CompiledGraph compile() throws GraphStateException {
SaverConfig saverConfig = SaverConfig.builder()
.register(SaverEnum.MEMORY.getValue(), new MemorySaver())
.build();
return compile(CompileConfig.builder().saverConfig(saverConfig).build());
}
MemorySaver 实现了 BaseCheckpointSaver,所以如果要自定义状态存储的位置,需要实现 BaseCheckpointSaver:
public interface BaseCheckpointSaver {
String THREAD_ID_DEFAULT = "$default";
record Tag(String threadId, Collection<Checkpoint> checkpoints) {
public Tag(String threadId, Collection<Checkpoint> checkpoints) {
this.threadId = threadId;
this.checkpoints = ofNullable(checkpoints).map(List::copyOf).orElseGet(List::of);
}
}
default Tag release(RunnableConfig config) throws Exception {
return null;
}
Collection<Checkpoint> list(RunnableConfig config);
Optional<Checkpoint> get(RunnableConfig config);
RunnableConfig put(RunnableConfig config, Checkpoint checkpoint) throws Exception;
boolean clear(RunnableConfig config);
default Optional<Checkpoint> getLast(LinkedList<Checkpoint> checkpoints, RunnableConfig config) {
return (checkpoints == null || checkpoints.isEmpty()) ? Optional.empty() : ofNullable(checkpoints.peek());
}
default LinkedList<Checkpoint> getLinkedList(List<Checkpoint> checkpoints) {
return Objects.nonNull(checkpoints) ? new LinkedList<>(checkpoints) : new LinkedList<>();
}
}
打印图
我们可以把定义好的状态图进行打印,更直观的看到当前图的情况。
@Bean("saveGraph")
public CompiledGraph saveGraph(ChatClient.Builder clientBuilder) throws GraphStateException{
KeyStrategyFactory keyStrategyFactory = () -> Map.of();
// 定义状态图
StateGraph stateGraph = new StateGraph("loopGraph", keyStrategyFactory);
stateGraph.addNode("对话存储", AsyncNodeAction.node_async(new NodeAction() {
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
String msg = state.value("msg","");
ArrayList<Object> historyMsg = state.value("historyMsg", new ArrayList<>());
historyMsg.add(msg);
return Map.of("historyMsg",historyMsg);
}
}));
// 定义边
stateGraph.addEdge(StateGraph.START,"对话存储");
stateGraph.addEdge("对话存储",StateGraph.END);
// 添加 PlantUML 打印
GraphRepresentation representation = stateGraph.getGraph(GraphRepresentation.Type.PLANTUML, "saveGraph");
log.info("\n=== expander UML Flow ===");
log.info(representation.content());
log.info("=============================\n");
return stateGraph.compile();
}
运行服务的时候会打印如下信息:
@startuml saveGraph
skinparam usecaseFontSize 14
skinparam usecaseStereotypeFontSize 12
skinparam hexagonFontSize 14
skinparam hexagonStereotypeFontSize 12
title "saveGraph"
footer
powered by spring-ai-alibaba
end footer
circle start<<input>> as __START__
circle stop as __END__
usecase "对话存储"<<Node>>
"__START__" -down-> "对话存储"
"对话存储" -down-> "__END__"
@enduml
然后把内容输入到 https://www.plantuml.com/plantuml 中就可以直观的看到当前的图。