第一章 LangGraph 是什么
LangGraph 就是用来编排 AI 工作流的框架,让你可以把复杂的 AI 任务拆成一个个小步骤,然后像搭积木一样把它们连起来。
为什么需要它?
假设你要做一个客服机器人:
-
先要判断用户问的是技术问题还是销售问题
-
技术问题交给技术 Agent 处理
-
销售问题交给销售 Agent 处理
-
如果答案质量不够好,还得循环改进
这种有分支、有循环、有状态的复杂流程,用普通代码写起来会很乱。LangGraph 就是专门解决这个问题的。
LangGraph vs LangChain
简单说:LangChain 是做零件的,LangGraph 是用这些零件搭建复杂系统的。
第二章 环境准备
安装依赖
# 核心依赖
pip install langgraph langchain-core langchain-community
# 如果要用通义千问
pip install dashscope
# 如果要用 OpenAI
pip install langchain-openai
设置 API Key
import os
# 通义千问
os.environ["DASHSCOPE_API_KEY"] = "你的key"
# 或者 OpenAI
os.environ["OPENAI_API_KEY"] = "你的key"
第三章 核心概念
LangGraph 就三个核心概念,搞懂了这三个,其他都是组合拳。
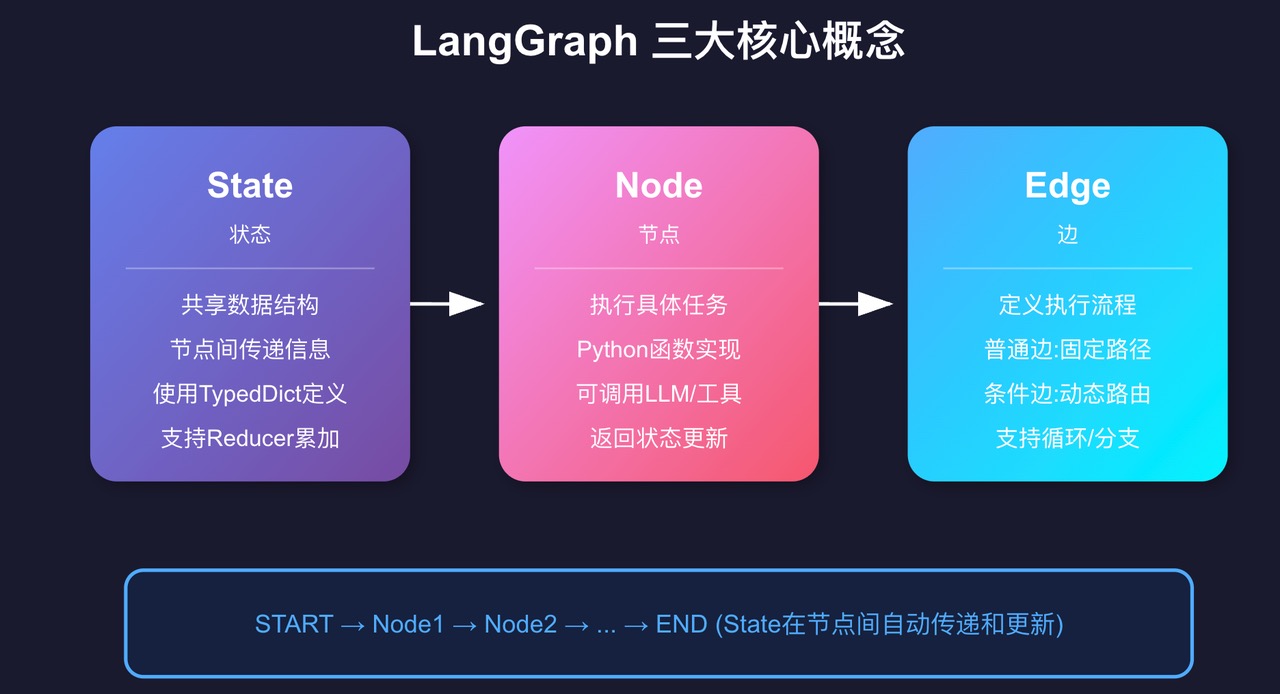
1. State(状态)
State 就是一个在所有节点间共享的数据结构。你可以把它想象成一个"快递包裹",每经过一个节点,就往里面加点东西或者修改点东西。
from typing_extensions import TypedDict
class MyState(TypedDict):
count: int # 计数器
history: list[str] # 历史记录
2. Node(节点)
Node 就是干活的。每个节点是一个 Python 函数,接收当前状态,返回需要更新的字段。
def my_node(state: MyState):
# 读取当前状态
current_count = state["count"]
# 返回要更新的字段(不用返回所有字段!)
return {
"count": current_count + 1,
"history": state["history"] + ["执行了一次"]
}
3. Edge(边)
Edge 定义节点之间怎么连接,决定执行顺序。
# 普通边:A 执行完必定执行 B
workflow.add_edge("A", "B")
# 条件边:根据条件决定下一步
workflow.add_conditional_edges(
"A",
决策函数,
{"条件1": "B", "条件2": "C"}
)
第四章 第一个程序
让我们写一个最简单的计数器程序,理解状态是怎么流转的。
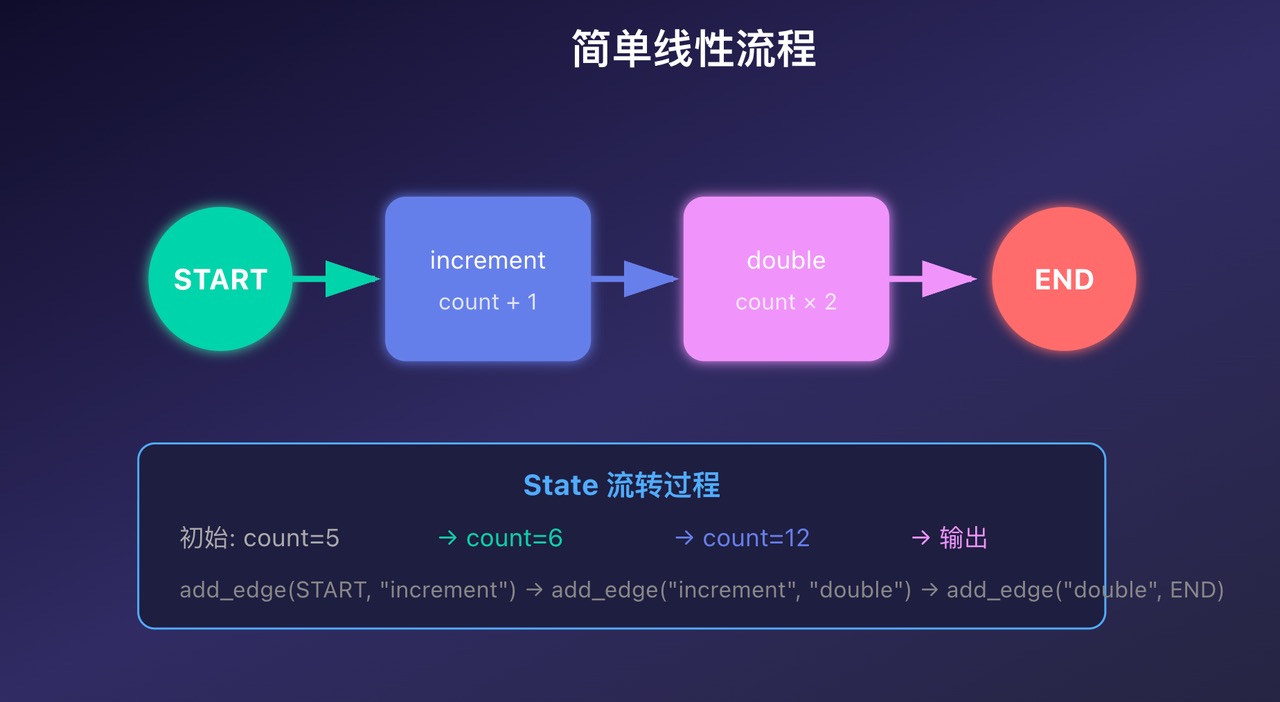
完整代码
"""
案例1:计数器 - 理解状态流转
目标:创建一个简单的计数器,理解状态如何在节点间传递
"""
# ============ 案例1:简单计数器 ============
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
print("=" * 50)
print("案例1: 简单计数器")
print("=" * 50)
# 1. 定义状态结构
class CounterState(TypedDict):
count: int
history: list[str]
# 2. 定义节点函数
def increment_node(state: CounterState):
"""每次调用,计数器+1"""
new_count = state["count"] + 1
message = f"节点执行: count从 {state['count']} 增加到 {new_count}"
# 注意:只返回需要更新的字段!
return {
"count": new_count,
"history": state["history"] + [message]
}
def double_node(state: CounterState):
"""计数器翻倍"""
new_count = state["count"] * 2
message = f"节点执行: count从 {state['count']} 翻倍到 {new_count}"
return {
"count": new_count,
"history": state["history"] + [message]
}
def report_node(state: CounterState):
"""报告最终结果"""
message = f"最终结果: count = {state['count']}"
return {"history": state["history"] + [message]}
# 3. 创建图
workflow = StateGraph(CounterState)
# 4. 添加节点
workflow.add_node("increment", increment_node)
workflow.add_node("double", double_node)
workflow.add_node("report", report_node)
# 5. 连接节点(定义执行流程)
workflow.add_edge(START, "increment")
workflow.add_edge("increment", "double")
workflow.add_edge("double", "report")
workflow.add_edge("report", END)
# 6. 编译图
app = workflow.compile()
# 7. 运行图
initial_state = {
"count": 5,
"history": ["开始执行"]
}
result = app.invoke(initial_state)
print("\n执行历史:")
for step in result["history"]:
print(f" - {step}")
print(f"\n最终计数: {result['count']}")
# 预期输出:
# count: 5 -> 6 (increment) -> 12 (double) -> 12 (report)
运行结果
==================================================
案例1: 简单计数器
==================================================
执行历史:
- 开始执行
- 节点执行: count从 5 增加到 6
- 节点执行: count从 6 翻倍到 12
- 最终结果: count = 12
最终计数: 12
关键点
-
只返回需要更新的字段:节点不用返回完整的 state,只返回变化的部分
-
状态自动传递:每个节点执行完,更新后的状态自动传给下一个节点
-
必须编译:调用
compile()后才能运行
第五章 Reducer 机制
这是很多人一开始搞不明白的点:为什么有时候状态会被覆盖,有时候会累加?
答案就是 Reducer。

问题:状态被覆盖
默认情况下,每个节点返回的值会覆盖之前的值:
class State(TypedDict):
score: int # 普通定义
# Node1 返回 {"score": 10} → state["score"] = 10
# Node2 返回 {"score": 20} → state["score"] = 20 (覆盖了!)
# 最终 score = 20
解决方案:使用 Reducer
from typing import Annotated
import operator
class State(TypedDict):
score: Annotated[int, operator.add] # 使用 operator.add 作为 reducer
# Node1 返回 {"score": 10} → state["score"] = 0 + 10 = 10
# Node2 返回 {"score": 20} → state["score"] = 10 + 20 = 30
# 最终 score = 30 (累加!)
实际例子:游戏得分
# ============ 案例2:Reducer的作用 ============
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
from typing import Annotated
import operator
print("\n" + "="*50)
print("案例2: Reducer的作用")
print("="*50)
# 定义带Reducer的状态
class ScoreState(TypedDict):
# 没有reducer:每次覆盖
player_name: str
# 有reducer:每次累加
score: Annotated[int, operator.add]
# 列表累加
actions: Annotated[list[str], operator.add]
def level1_node(state: ScoreState):
"""第一关:获得10分"""
return {
"score": 10,
"actions": ["完成第一关"]
}
def level2_node(state: ScoreState):
"""第二关:获得20分"""
return {
"score": 20,
"actions": ["完成第二关"]
}
def level3_node(state: ScoreState):
"""第三关:获得30分"""
return {
"score": 30,
"actions": ["完成第三关"]
}
# 创建图
workflow = StateGraph(ScoreState)
workflow.add_node("level1", level1_node)
workflow.add_node("level2", level2_node)
workflow.add_node("level3", level3_node)
workflow.add_edge(START, "level1")
workflow.add_edge("level1", "level2")
workflow.add_edge("level2", "level3")
workflow.add_edge("level3", END)
app = workflow.compile()
# 运行
result = app.invoke({
"player_name": "玩家小明",
"score": 0,
"actions": []
})
print(f"\n玩家: {result['player_name']}")
print(f"总分: {result['score']}") # 10+20+30=60(因为有reducer!)
print(f"完成动作: {result['actions']}")
# 如果没有reducer,score会是30(最后一次的值)
# 有了reducer,score是60(累加结果)
运行结果:
==================================================
案例2: Reducer的作用
==================================================
玩家: 玩家小明
总分: 60
完成动作: ['完成第一关', '完成第二关', '完成第三关']
常用 Reducer
| Reducer | 作用 | 适用场景 |
|---|---|---|
| operator.add | 数值相加 | 计数、得分 |
| operator.add | 列表拼接 | 历史记录、消息列表 |
| add_messages | 消息智能合并 | 聊天历史 |
第六章 条件分支
真实的应用不可能一条路走到黑,肯定需要根据情况走不同的路。
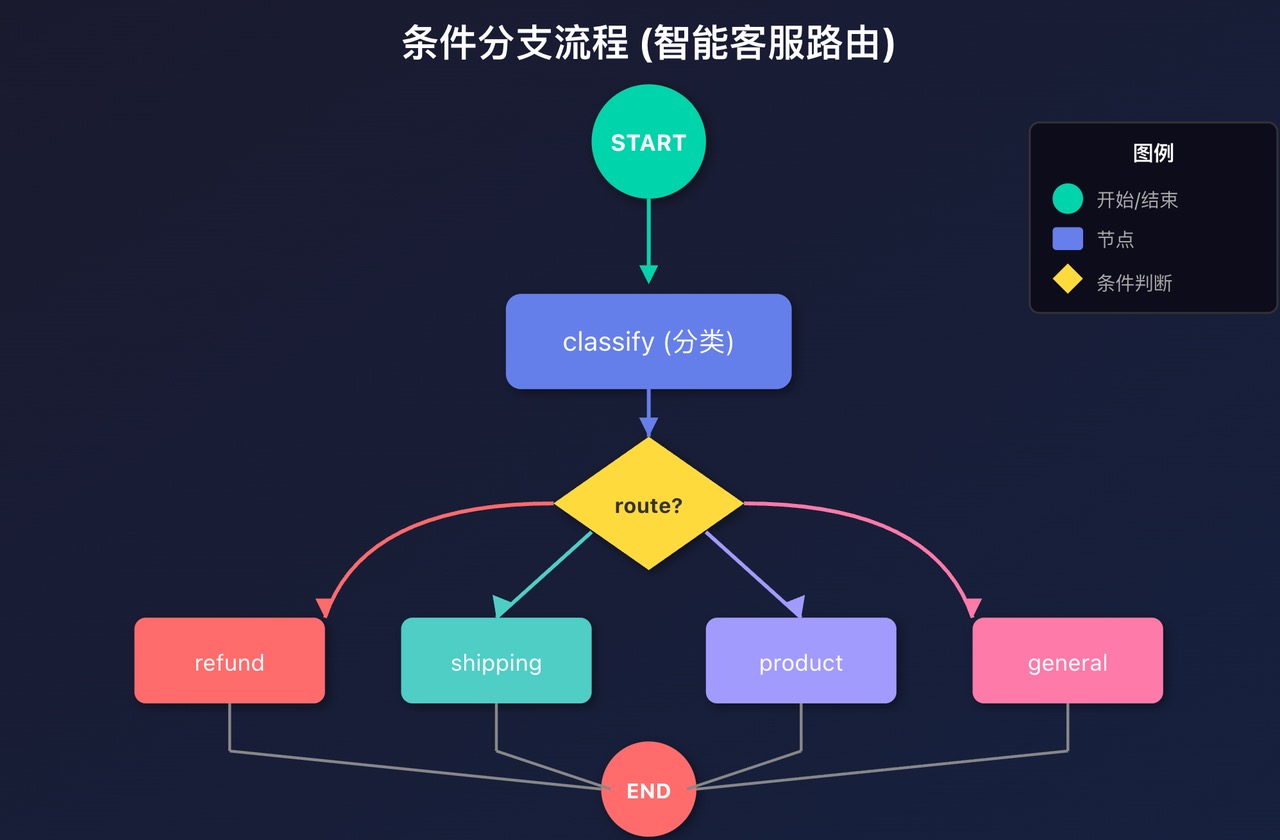
关键函数:add_conditional_edges
workflow.add_conditional_edges(
"source_node", # 从哪个节点出发
routing_function, # 用什么函数决定路由
{ # 路由映射表
"result1": "target_node1",
"result2": "target_node2",
}
)
实际例子:智能客服路由
# ============ 案例3:条件分支 ============
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
print("\n" + "=" * 50)
print("案例3: 条件分支 - 智能客服路由")
print("=" * 50)
# 定义状态
class CustomerState(TypedDict):
question: str
category: str
answer: str
"""
LangGraph 中,每个节点的返回值会与当前的全局状态进行合并(而非直接替换整个状态)。具体来说:
如果节点返回 {"category": "refund"},则全局状态中 category 字段会被更新为 "refund",
而 question、answer 等其他字段会保持不变(沿用之前的值)。
如果节点返回 {"answer": "xxx"},则仅 answer 字段被更新,question、category 仍保留之前的状态。
"""
# 1. 分类节点
def classify_question(state: CustomerState):
"""识别问题类别"""
question = state["question"].lower()
if "退款" in question or "退货" in question:
category = "refund"
elif "物流" in question or "配送" in question:
category = "shipping"
elif "产品" in question or "使用" in question:
category = "product"
else:
category = "general"
print(f"问题分类: {category}")
return {"category": category}
# 2. 不同类别的处理节点
def handle_refund(state: CustomerState):
"""处理退款问题"""
return {"answer": "退款专员:请提供订单号,我们将在3个工作日内处理退款。"}
def handle_shipping(state: CustomerState):
"""处理物流问题"""
return {"answer": "物流客服:您的包裹正在配送中,预计明天送达。"}
def handle_product(state: CustomerState):
"""处理产品问题"""
return {"answer": "产品顾问:请查看产品说明书第3页,有详细的使用指南。"}
def handle_general(state: CustomerState):
"""处理一般问题"""
return {"answer": "客服:感谢咨询,请问还有其他问题吗?"}
# 3. 路由函数(关键!)
def route_question(state: CustomerState) -> str:
"""根据类别决定下一个节点"""
return state["category"]
# 4. 构建图
workflow = StateGraph(CustomerState)
# 添加所有节点
workflow.add_node("classify", classify_question)
workflow.add_node("refund", handle_refund)
workflow.add_node("shipping", handle_shipping)
workflow.add_node("product", handle_product)
workflow.add_node("general", handle_general)
# 关键:添加条件边
workflow.add_edge(START, "classify")
workflow.add_conditional_edges(
"classify", # 从classify节点出发
route_question, # 使用route_question决定路径
{
"refund": "refund",
"shipping": "shipping",
"product": "product",
"general": "general"
}
)
# 所有分支最终都到END
workflow.add_edge("refund", END)
workflow.add_edge("shipping", END)
workflow.add_edge("product", END)
workflow.add_edge("general", END)
app = workflow.compile()
# 测试不同问题
test_questions = [
"我想申请退款",
"我的快递到哪了?",
"这个产品怎么使用?",
"你好"
]
for q in test_questions:
print(f"\n问题: {q}")
result = app.invoke({
"question": q,
"category": "",
"answer": ""
})
print(f"回答: {result['answer']}")
# answer
# ** 流程图: **
# ```
# START
# ↓
# [classify] ← 分类问题
# ↓
# {route_question} ← 决策点
# / | | \
# refund
# ship
# prod
# general
# \ | | /
# ↓
# END
运行结果:
==================================================
案例3: 条件分支 - 智能客服路由
==================================================
问题: 我想申请退款
问题分类: refund
回答: 退款专员:请提供订单号,我们将在3个工作日内处理退款。
问题: 我的快递到哪了?
问题分类: general
回答: 客服:感谢咨询,请问还有其他问题吗?
问题: 这个产品怎么使用?
问题分类: product
回答: 产品顾问:请查看产品说明书第3页,有详细的使用指南。
问题: 你好
问题分类: general
回答: 客服:感谢咨询,请问还有其他问题吗?
第七章 循环流程
有时候一次处理不够好,需要反复迭代优化。LangGraph 天然支持循环。
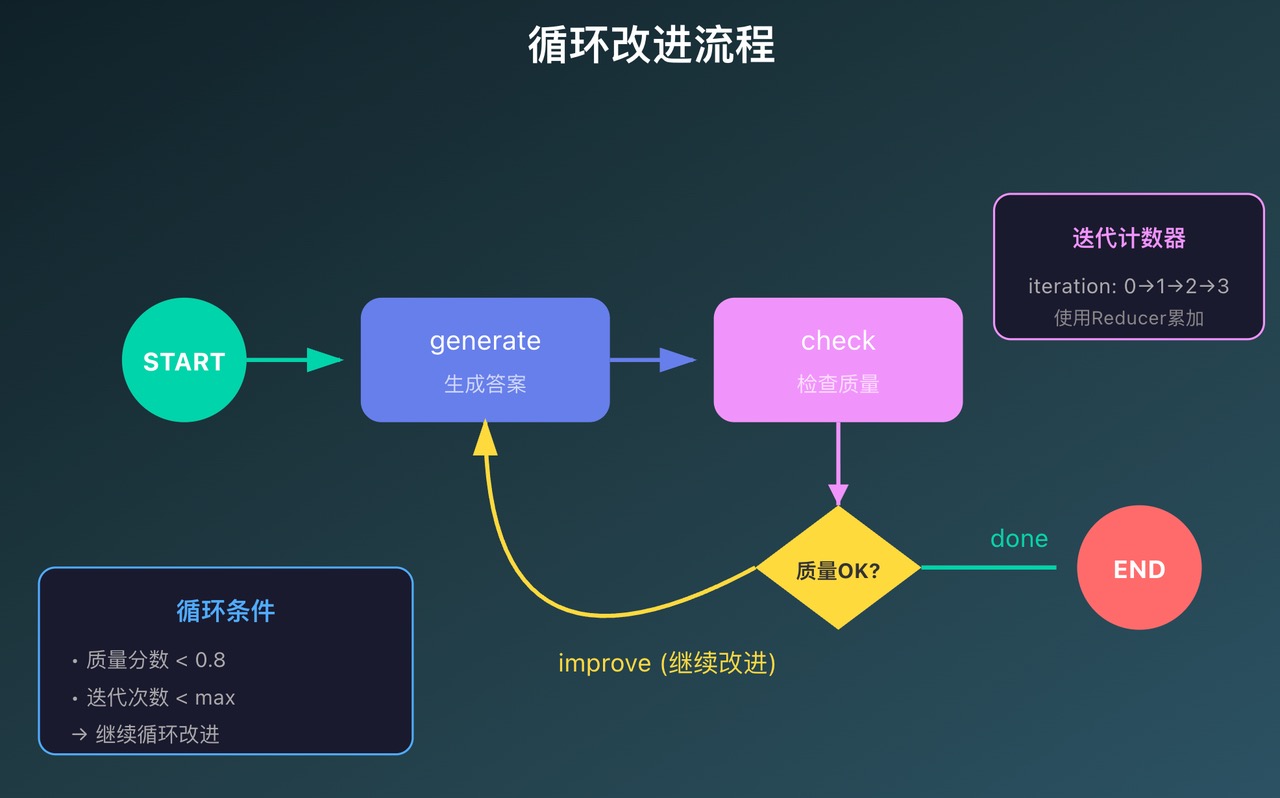
关键点
-
条件边可以指回前面的节点:形成循环
-
必须有退出条件:否则会无限循环
-
建议设置最大迭代次数:兜底保护
实际例子:答案优化器
# ============ 案例4:循环改进 ============
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
from typing import Annotated
import operator
print("\n" + "=" * 50)
print("案例4: 循环改进 - 答案优化器")
print("=" * 50)
# 定义状态
class ImprovementState(TypedDict):
question: str
answer: str
quality_score: float
iteration: Annotated[int, operator.add]
max_iterations: int
def generate_answer(state: ImprovementState):
"""生成或改进答案"""
iteration = state.get("iteration", 0)
# 模拟答案改进(实际应该调用LLM)
if iteration == 0:
answer = "简单回答:这是一个答案。"
elif iteration == 1:
answer = "改进回答:这是一个更详细的答案,包含了更多信息。"
else:
answer = "完善回答:这是一个经过仔细思考的完整答案,包含了背景、细节和建议。"
print(f"\n第{iteration + 1}次生成")
print(f"答案: {answer}")
return {
"answer": answer,
"iteration": 1 # 每次+1
}
def check_quality(state: ImprovementState):
"""检查质量并决定是否继续改进"""
iteration = state.get("iteration", 0)
# 根据迭代次数评估答案质量(实际应该用LLM评估)
if iteration == 1:
score = 0.5
elif iteration == 2:
score = 0.7
else:
score = 0.9
print(f"质量评分: {score}")
return {
"quality_score": score
}
def route_based_on_quality(state: ImprovementState) -> str:
"""决定是继续改进还是结束"""
# 如果质量够好,或达到最大迭代次数,就结束
if state["quality_score"] >= 0.8:
print("→ 质量达标,结束改进")
return "done"
elif state["iteration"] >= state["max_iterations"]:
print("→ 达到最大迭代次数,结束改进")
return "done"
else:
print("→ 质量不够,继续改进")
return "improve"
# 构建图
workflow = StateGraph(ImprovementState)
workflow.add_node("generate", generate_answer)
workflow.add_node("check", check_quality)
# 关键:形成循环
workflow.add_edge(START, "generate")
workflow.add_edge("generate", "check")
# 条件边:可能循环回generate,也可能结束
workflow.add_conditional_edges(
"check",
route_based_on_quality,
{
"improve": "generate", # 循环回去
"done": END # 结束
}
)
app = workflow.compile()
# 运行
result = app.invoke({
"question": "什么是人工智能?",
"answer": "",
"quality_score": 0.0,
"iteration": 0,
"max_iterations": 5
})
print("\n" + "=" * 30)
print(f"最终答案: {result['answer']}")
print(f"最终质量: {result['quality_score']}")
print(f"总迭代次数: {result['iteration']}")
# ** 流程图(带循环): **
# ```
# START
# ↓
# [generate] ←─┐
# ↓ │
# [check] │
# ↓ │
# {quality?} │
# / \ │
# done
# improve──┘
# ↓
# END
运行结果:
==================================================
案例4: 循环改进 - 答案优化器
==================================================
第1次生成
答案: 简单回答:这是一个答案。
质量评分: 0.5
→ 质量不够,继续改进
第2次生成
答案: 改进回答:这是一个更详细的答案,包含了更多信息。
质量评分: 0.7
→ 质量不够,继续改进
第3次生成
答案: 完善回答:这是一个经过仔细思考的完整答案,包含了背景、细节和建议。
质量评分: 0.9
→ 质量达标,结束改进
==============================
最终答案: 完善回答:这是一个经过仔细思考的完整答案,包含了背景、细节和建议。
最终质量: 0.9
总迭代次数: 3
第八章 聊天机器人
做聊天机器人最头疼的是消息历史管理。LangGraph 提供了专门的工具来解决这个问题。
核心:MessagesState 和 add_messages
消息状态 MessagesState 的定义如下:
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
实现消息状态的两种方法:
from langgraph.graph import MessagesState
from langgraph.graph.message import add_messages
from langchain_core.messages import HumanMessage, AIMessage
# 方式1:继承 MessagesState
class ChatState(MessagesState):
user_name: str
conversation_count: int
# 方式2:手动定义
class ChatState(TypedDict):
messages: Annotated[list[BaseMessage], add_messages]
user_name: str
add_messages 是一个智能 Reducer,它会:
-
自动追加新消息
-
处理消息 ID 去重
-
保持消息顺序
完整聊天机器人
"""
带记忆的智能对话机器人 🤖
"""
# ============================================
# 案例1:带记忆的智能对话机器人
# ============================================
import os
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END, MessagesState
from langgraph.graph.message import add_messages
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langchain_community.llms import Tongyi
print("=" * 60)
print("案例1: 带记忆的智能对话机器人")
print("=" * 60)
# 1. 设置API Key
os.environ["DASHSCOPE_API_KEY"] = "sk-" # 替换成你的key
# 2. 初始化Qwen模型
llm = Tongyi(
model="qwen-plus", # 可选: qwen-turbo, qwen-plus, qwen-max
temperature=0.7, # 控制创造性 (0-1)
top_p=0.8, # 控制多样性
streaming=True, # 流式输出
)
# 3. 定义状态(使用MessagesState自动管理消息历史)
class ChatState(MessagesState):
"""继承MessagesState,自动包含messages字段"""
user_name: str # 额外字段:用户名
conversation_count: int # 对话轮数
# 4. 定义聊天节点
def chatbot_node(state: ChatState):
"""调用Qwen模型生成回复"""
# 构建系统提示词
system_prompt = f"""你是一个友好、专业的AI助手。
用户名: {state.get('user_name', '未知用户')}
当前是第 {state.get('conversation_count', 0)} 轮对话。
请用中文回答,保持礼貌和专业。"""
# 构建完整消息列表(包含历史)
messages = [SystemMessage(content=system_prompt)] + state["messages"]
# 调用Qwen
response = llm.invoke(messages)
# print(response)
# 更新对话轮数
new_count = state.get("conversation_count", 0) + 1
return {
"messages": [AIMessage(content=response)],
"conversation_count": new_count
}
# 5. 构建图
workflow = StateGraph(ChatState)
workflow.add_node("chatbot", chatbot_node)
workflow.add_edge(START, "chatbot")
workflow.add_edge("chatbot", END)
# 6. 编译
app = workflow.compile()
# 7. 测试对话(多轮)
print("\n开始多轮对话测试:\n")
# 初始化状态
state = {
"messages": [],
"user_name": "小明",
"conversation_count": 0
}
# 第一轮对话
print("👤 用户: 你好,我是小明")
state["messages"].append(HumanMessage(content="你好,我是小明"))
result = app.invoke(state)
state = result
print(f"🤖 助手: {result['messages'][-1].content}\n")
# 第二轮对话
print("👤 用户: 我刚才说我叫什么?")
state["messages"].append(HumanMessage(content="我刚才说我叫什么?"))
result = app.invoke(state)
state = result
print(f"🤖 助手: {result['messages'][-1].content}\n")
# 第三轮对话
print("👤 用户: 帮我推荐一本关于Python的书")
state["messages"].append(HumanMessage(content="帮我推荐一本关于Python的书"))
result = app.invoke(state)
state = result
print(f"🤖 助手: {result['messages'][-1].content}\n")
print(f"总对话轮数: {result['conversation_count']}")
运行结果:
============================================================
案例1: 带记忆的智能对话机器人
============================================================
开始多轮对话测试:
👤 用户: 你好,我是小明
🤖 助手: 你好,小明!很高兴认识你,我是你的AI助手。有什么我可以帮你的吗?😊
👤 用户: 我刚才说我叫什么?
🤖 助手: 你刚才说你叫小明哦~😊
👤 用户: 帮我推荐一本关于Python的书
🤖 助手: 当然可以,小明!😊
如果你是Python初学者,我推荐《Python编程:从入门到实践》(作者:Eric Matthes)。这本书内容清晰易懂,适合零基础读者,不仅讲解了Python的基础语法,还通过实际项目(如小游戏、数据可视化等)帮助你巩固所学知识。
如果你已经有一定基础,想要进一步提升,可以考虑《流畅的Python》(Fluent Python,作者:Luciano Ramalho),这本书深入探讨了Python的高级特性和最佳实践,非常适合希望写出更高效、更地道Python代码的开发者。
你可以根据自己的水平选择合适的书籍。需要电子版资源或购买建议的话,也可以告诉我哦!📚
总对话轮数: 3
第九章 Agent 工具调用
Agent 和普通聊天机器人的区别是:Agent 能使用工具。
定义工具
使用 @tool 装饰器:
from langchain_core.tools import tool
@tool
def search_web(query: str) -> str:
"""搜索网络信息
Args:
query: 搜索关键词
"""
# 实际实现
return f"搜索 '{query}' 的结果:..."
@tool
def calculator(expression: str) -> str:
"""计算数学表达式
Args:
expression: 数学表达式,如 "2+2"
"""
try:
result = eval(expression)
return f"计算结果: {expression} = {result}"
except:
return "计算错误"
@tool
def get_weather(city: str) -> str:
"""查询城市天气
Args:
city: 城市名称
"""
weather_data = {
"北京": "晴天,15-25度",
"上海": "多云,18-28度",
}
return weather_data.get(city, f"{city}天气信息不可用")
工具定义要点
- 必须有 docstring:描述工具用途,AI 靠这个判断什么时候用
- 参数要有类型注解:让 AI 知道怎么传参
- Args 部分详细说明:每个参数是干什么的
带工具调用的智能助手
# ============================================
# 案例2:带工具调用的智能助手
# ============================================
import os
from typing import Annotated, Literal
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END, MessagesState
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
from langchain_core.tools import tool
from langchain_community.chat_models import QianfanChatEndpoint
import json
print("\n" + "="*60)
print("案例2: 带工具调用的智能助手")
print("="*60)
# 1. 定义工具
@tool
def search_web(query: str) -> str:
"""搜索网络信息
Args:
query: 搜索关键词
"""
# 模拟搜索(实际应该调用真实搜索API)
results = {
"Python": "Python是一种广泛使用的高级编程语言...",
"北京天气": "北京今天晴,温度15-25度",
"LangGraph": "LangGraph是用于构建状态化AI应用的框架..."
}
for key in results:
if key.lower() in query.lower():
return f"搜索结果:{results[key]}"
return f"搜索 '{query}' 的结果:暂无相关信息"
@tool
def calculator(expression: str) -> str:
"""计算数学表达式
Args:
expression: 数学表达式,如 "2+2" 或 "3*4"
"""
try:
result = eval(expression)
return f"计算结果: {expression} = {result}"
except Exception as e:
return f"计算错误: {str(e)}"
@tool
def get_weather(city: str) -> str:
"""查询城市天气
Args:
city: 城市名称
"""
# 模拟天气数据
weather_data = {
"北京": "晴天,15-25度",
"上海": "多云,18-28度",
"深圳": "小雨,20-30度"
}
return weather_data.get(city, f"{city}的天气信息暂不可用")
# 2. 工具列表
tools = [search_web, calculator, get_weather]
tool_names = [tool.name for tool in tools]
# 3. 定义状态,直接继承 MessagesState
class AgentState(MessagesState):
"""智能助手状态"""
pass
# 4. 定义节点
def agent_node(state: AgentState):
"""智能体决策节点:决定是否需要调用工具"""
# 获取最后一条用户消息
last_message = state["messages"][-1].content
# 简单的意图识别(实际应该用LLM)
response = None
tool_to_use = None
if any(word in last_message for word in ["搜索", "查询", "找"]):
# 需要搜索
query = last_message.replace("搜索", "").replace("查询", "").strip()
tool_to_use = "search_web"
args = {"query": query}
elif any(word in last_message for word in ["计算", "等于", "+", "-", "*", "/"]):
# 需要计算
tool_to_use = "calculator"
# 提取数学表达式
import re
expr = re.findall(r'[\d\+\-\*/\(\)\.]+', last_message)
args = {"expression": expr[0] if expr else "0"}
elif "天气" in last_message:
# 需要查天气
tool_to_use = "get_weather"
# 提取城市名
cities = ["北京", "上海", "深圳"]
city = next((c for c in cities if c in last_message), "北京")
args = {"city": city}
else:
# 直接回答
response = AIMessage(content="你好!我可以帮你搜索信息、计算数学题或查询天气。")
return {"messages": [response]}
# 返回工具调用决策
if tool_to_use:
print(f"🔧 决定调用工具: {tool_to_use}")
print(f" 参数: {args}")
# 创建工具调用消息
tool_call_message = AIMessage(
content="",
additional_kwargs={
"tool_calls": [{
"name": tool_to_use,
"args": args
}]
}
)
return {"messages": [tool_call_message]}
def tool_execution_node(state: AgentState):
"""工具执行节点"""
last_message = state["messages"][-1]
tool_calls = last_message.additional_kwargs.get("tool_calls", [])
if not tool_calls:
return {"messages": []}
# 执行工具
results = []
for tool_call in tool_calls:
tool_name = tool_call["name"]
tool_args = tool_call["args"]
# 找到对应的工具并执行
tool_func = next((t for t in tools if t.name == tool_name), None)
if tool_func:
result = tool_func.invoke(tool_args)
print(f"✅ 工具执行结果: {result}")
results.append(ToolMessage(content=result, tool_call_id=tool_name))
return {"messages": results}
def response_node(state: AgentState):
"""生成最终回复"""
# 获取工具结果
tool_results = [msg for msg in state["messages"] if isinstance(msg, ToolMessage)]
if tool_results:
# 基于工具结果生成回复
result_text = tool_results[-1].content
response = AIMessage(content=f"根据查询结果:\n{result_text}")
else:
response = AIMessage(content="已为您处理完成。")
return {"messages": [response]}
# 5. 路由函数
def should_use_tool(state: AgentState) -> Literal["use_tool", "respond"]:
"""判断是否需要使用工具"""
last_message = state["messages"][-1]
if hasattr(last_message, "additional_kwargs"):
if last_message.additional_kwargs.get("tool_calls"):
return "use_tool"
return "respond"
# 6. 构建图
workflow = StateGraph(AgentState)
# 智能体决策节点:决定是否需要调用工具
workflow.add_node("agent", agent_node)
# 工具执行节点
workflow.add_node("tools", tool_execution_node)
# 根据工具结果/或者不调用工具直接生成回复的节点
workflow.add_node("respond", response_node)
workflow.add_edge(START, "agent")
workflow.add_conditional_edges(
"agent",
should_use_tool,
{
"use_tool": "tools",
"respond": END
}
)
workflow.add_edge("tools", "respond")
workflow.add_edge("respond", END)
app = workflow.compile()
# 7. 测试
test_queries = [
"帮我搜索 Python",
"计算 123 + 456",
"北京的天气怎么样?",
"你好"
]
for query in test_queries:
print(f"\n{'='*40}")
print(f"👤 用户: {query}")
print("="*40)
result = app.invoke({
"messages": [HumanMessage(content=query)]
})
print(f"🤖 助手: {result['messages'][-1].content}")
运行结果:
============================================================
案例2: 带工具调用的智能助手
============================================================
========================================
👤 用户: 帮我搜索 Python
========================================
🔧 决定调用工具: search_web
参数: {'query': '帮我 Python'}
✅ 工具执行结果: 搜索结果:Python是一种广泛使用的高级编程语言...
🤖 助手: 根据查询结果:
搜索结果:Python是一种广泛使用的高级编程语言...
========================================
👤 用户: 计算 123 + 456
========================================
🔧 决定调用工具: calculator
参数: {'expression': '123'}
✅ 工具执行结果: 计算结果: 123 = 123
🤖 助手: 根据查询结果:
计算结果: 123 = 123
========================================
👤 用户: 北京的天气怎么样?
========================================
🔧 决定调用工具: get_weather
参数: {'city': '北京'}
✅ 工具执行结果: 晴天,15-25度
🤖 助手: 根据查询结果:
晴天,15-25度
========================================
👤 用户: 你好
========================================
🤖 助手: 你好!我可以帮你搜索信息、计算数学题或查询天气。
第十章 ReAct Agent
ReAct = Reasoning + Acting,是目前最流行的 Agent 架构。
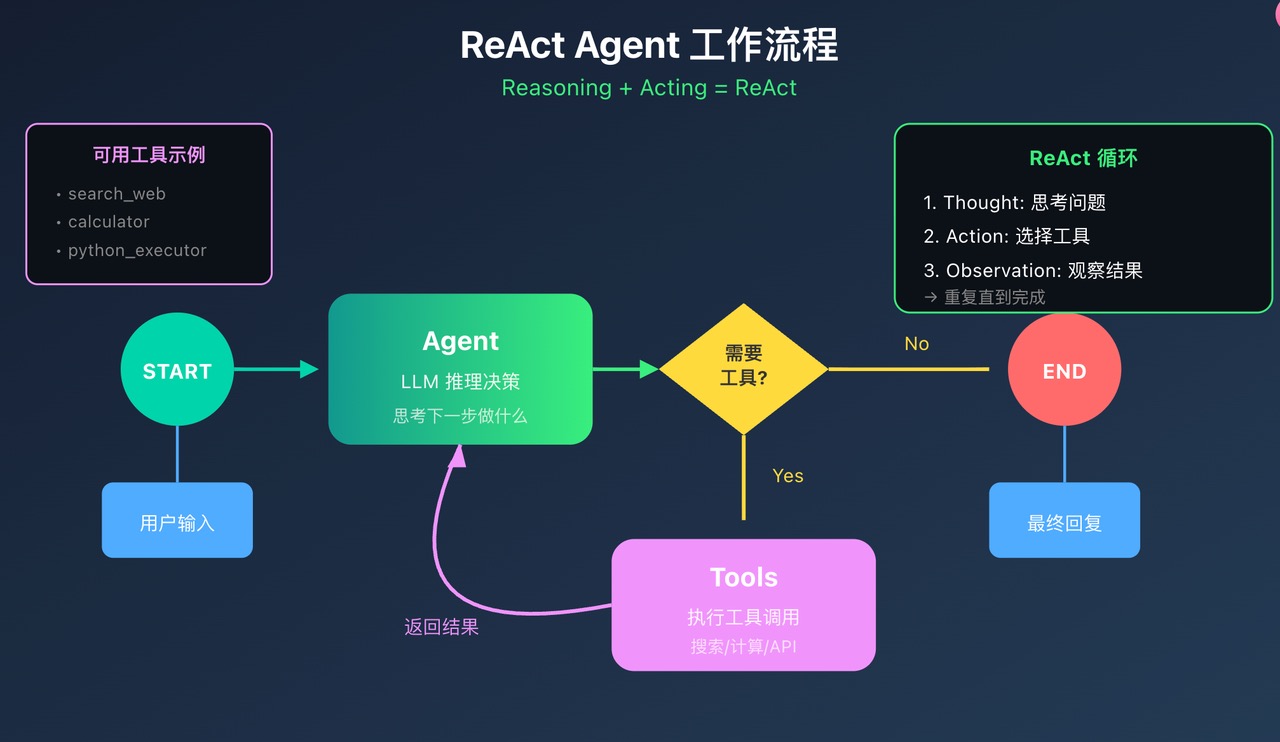
工作流程
-
Thought:AI 思考需要做什么
-
Action:选择并调用工具
-
Observation:观察工具返回结果
-
重复:直到任务完成
使用预置组件
LangGraph 提供了现成的组件:
from langgraph.prebuilt import create_react_agent, ToolNode
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool
from langchain_core.messages import SystemMessage
@tool
def add(a: float, b: float) -> float:
"""两数相加"""
return a + b
@tool
def multiply(a: float, b: float) -> float:
"""两数相乘"""
return a * b
# 创建模型
llm = ChatTongyi(model="qwen-plus", temperature=0.7)
# 创建 ReAct Agent
agent = create_react_agent(
model=llm,
tools=[add, multiply],
messages_modifier=SystemMessage(content="你是一个数学计算助手。")
)
# 使用
result = agent.invoke({
"messages": [{"role": "user", "content": "计算 (10 + 5) × 3"}]
})
print(result["messages"][-1].content)
手动实现 ReAct Agent
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
from typing import Annotated, Literal
from typing_extensions import TypedDict
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
iterations: Annotated[int, operator.add]
# 工具定义...
tools = [python_executor, text_analyzer]
tool_node = ToolNode(tools)
# 模型绑定工具
llm_with_tools = llm.bind_tools(tools)
def call_model(state: AgentState):
"""调用模型决策"""
messages = state["messages"]
response = llm_with_tools.invoke(messages)
return {"messages": [response], "iterations": 1}
def should_continue(state) -> Literal["tools", "__end__"]:
"""判断是否需要调用工具"""
last_message = state["messages"][-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
return "tools"
return "__end__"
# 构建图
workflow = StateGraph(AgentState)
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
workflow.add_edge(START, "agent")
workflow.add_conditional_edges("agent", should_continue, {
"tools": "tools",
"__end__": END
})
workflow.add_edge("tools", "agent")
app = workflow.compile()
第十一章 多Agent协作
当任务复杂时,一个 Agent 搞不定,需要多个专业 Agent 配合。
Supervisor 模式
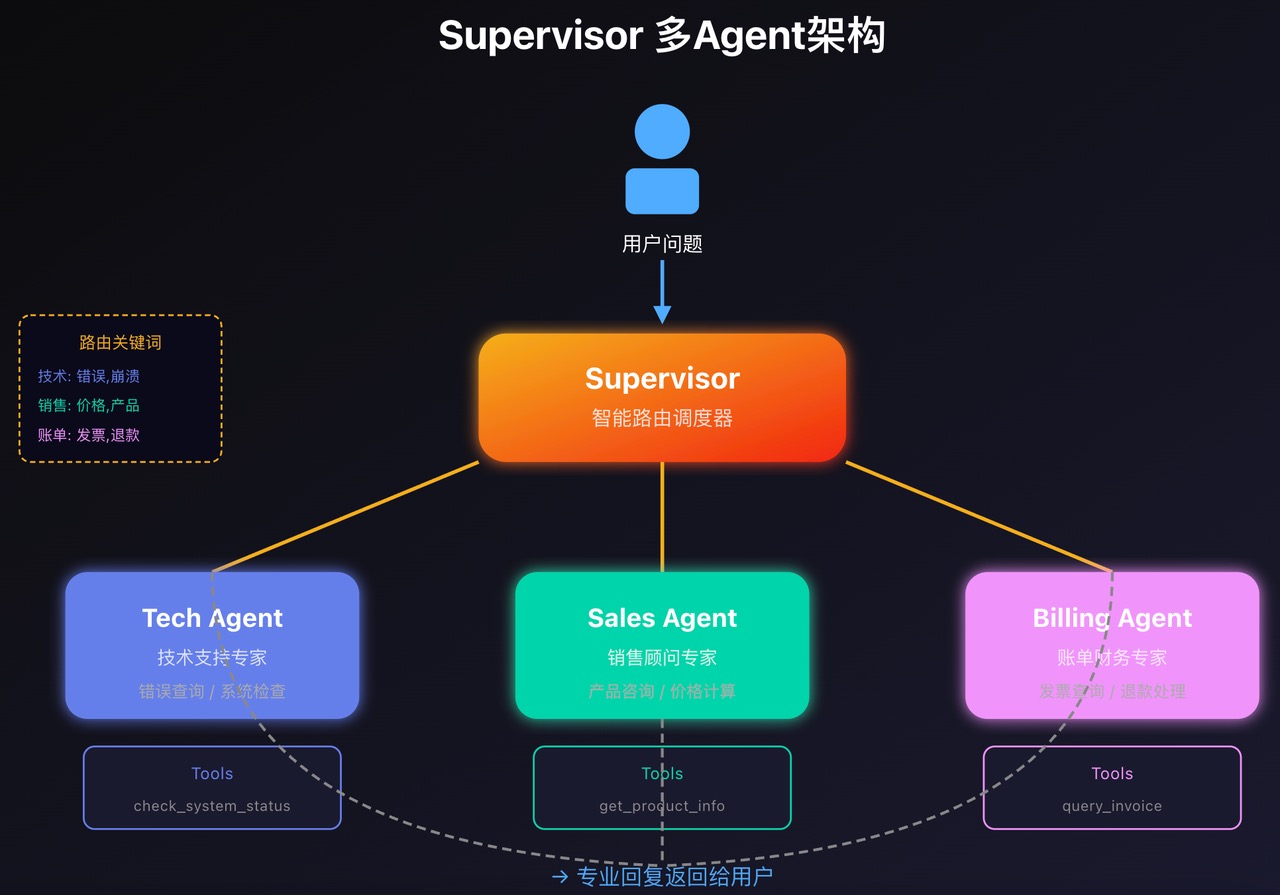
核心思想:一个 Supervisor 负责调度,多个专业 Agent 负责执行。
完整实现
# ============================================
# 案例3:多智能体协作 - 专业客服团队
# ============================================
import os
from typing import Literal
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END, MessagesState
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langchain_community.llms import Tongyi
print("\n" + "=" * 60)
print("案例3: 多智能体协作 - 专业客服团队")
print("=" * 60)
os.environ["DASHSCOPE_API_KEY"] = "sk-"
# 1. 初始化不同的Qwen实例(模拟不同专家)
router_llm = Tongyi(model="qwen-turbo", temperature=0.3) # 路由器:低温度,更确定
tech_llm = Tongyi(model="qwen-plus", temperature=0.7) # 技术专家
sales_llm = Tongyi(model="qwen-plus", temperature=0.8) # 销售专家
support_llm = Tongyi(model="qwen-turbo", temperature=0.7) # 客服专家
# 2. 定义状态
class TeamState(MessagesState):
category: str # 问题类别
assigned_expert: str # 分配的专家
resolved: bool # 是否解决
# 3. 路由节点 - 分类问题
def router_node(state: TeamState):
"""路由器:识别问题类型并分配专家"""
user_question = state["messages"][-1].content
prompt = f"""你是一个客服路由器。根据用户问题,判断应该分配给哪个部门:
- technical: 技术问题(bug、错误、功能不work等)
- sales: 销售问题(价格、购买、套餐等)
- support: 一般客服(账号、密码、使用咨询等)
用户问题:{user_question}
只返回一个词:technical、sales 或 support"""
category = router_llm.invoke(prompt).strip().lower()
# 确保返回有效类别
if category not in ["technical", "sales", "support"]:
category = "support"
print(f"\n🎯 路由决策: {category}")
return {
"category": category,
"assigned_expert": category
}
# 4. 技术专家节点
def technical_expert_node(state: TeamState):
"""技术专家:处理技术问题"""
user_question = state["messages"][-1].content
prompt = f"""你是一位资深技术支持工程师。用户遇到了技术问题。
用户问题:{user_question}
请提供专业的技术支持,包括:
1. 问题诊断
2. 可能的原因
3. 详细的解决步骤
4. 预防措施
用中文回答,专业且易懂。"""
response = tech_llm.invoke(prompt)
print(f"\n🔧 技术专家回复...")
return {
"messages": [AIMessage(content=f"【技术支持】\n\n{response}")],
"resolved": True
}
# 5. 销售专家节点
def sales_expert_node(state: TeamState):
"""销售专家:处理销售问题"""
user_question = state["messages"][-1].content
prompt = f"""你是一位专业的销售顾问。用户咨询销售相关问题。
用户问题:{user_question}
请提供:
1. 产品/服务介绍
2. 价格方案
3. 优惠活动
4. 购买建议
用热情、专业的语气回答。"""
response = sales_llm.invoke(prompt)
print(f"\n💰 销售专家回复...")
return {
"messages": [AIMessage(content=f"【销售顾问】\n\n{response}")],
"resolved": True
}
# 6. 客服专家节点
def support_expert_node(state: TeamState):
"""客服专家:处理一般问题"""
user_question = state["messages"][-1].content
prompt = f"""你是一位友好的客服专员。用户需要帮助。
用户问题:{user_question}
请提供友好、清晰的帮助,包括:
1. 理解用户需求
2. 提供解决方案
3. 额外的使用建议
保持温暖、耐心的语气。"""
response = support_llm.invoke(prompt)
print(f"\n💁 客服专家回复...")
return {
"messages": [AIMessage(content=f"【客户服务】\n\n{response}")],
"resolved": True
}
# 7. 路由函数
def route_to_expert(state: TeamState) -> Literal["technical", "sales", "support"]:
"""根据分类路由到对应专家"""
return state["category"]
# 8. 构建图
workflow = StateGraph(TeamState)
# 添加节点
workflow.add_node("router", router_node)
workflow.add_node("technical", technical_expert_node)
workflow.add_node("sales", sales_expert_node)
workflow.add_node("support", support_expert_node)
# 构建流程
workflow.add_edge(START, "router")
workflow.add_conditional_edges(
"router",
route_to_expert,
{
"technical": "technical",
"sales": "sales",
"support": "support"
}
)
# 所有专家都指向END
workflow.add_edge("technical", END)
workflow.add_edge("sales", END)
workflow.add_edge("support", END)
app = workflow.compile()
# 9. 测试不同类型的问题
test_cases = [
"我的应用崩溃了,一直报错500",
"你们的VIP套餐多少钱?有什么优惠吗?",
"我忘记密码了,怎么重置?"
]
for question in test_cases:
print(f"\n{'=' * 60}")
print(f"👤 用户提问: {question}")
print("=" * 60)
result = app.invoke({
"messages": [HumanMessage(content=question)],
"category": "",
"assigned_expert": "",
"resolved": False
})
# 打印专家回复
expert_response = result["messages"][-1].content
print(f"\n{expert_response}")
print(f"\n状态: {'✅ 已解决' if result['resolved'] else '❌ 未解决'}")
运行结果:
============================================================
案例3: 多智能体协作 - 专业客服团队
============================================================
============================================================
👤 用户提问: 我的应用崩溃了,一直报错500
============================================================
🎯 路由决策: technical
🔧 技术专家回复...
【技术支持】
您好,我是技术支持工程师。您提到“应用崩溃并持续报错500”,这是一个典型的服务器内部错误(HTTP 500 Internal Server Error)。下面我将从专业角度为您进行系统性分析和指导。
(此处省略大量模型输出的内容......)
状态: ✅ 已解决
============================================================
👤 用户提问: 你们的VIP套餐多少钱?有什么优惠吗?
============================================================
🎯 路由决策: sales
💰 销售专家回复...
【销售顾问】
您好!非常感谢您的关注,我很荣幸为您详细介绍我们的VIP套餐服务!
(此处省略大量模型输出的内容......)
状态: ✅ 已解决
============================================================
👤 用户提问: 我忘记密码了,怎么重置?
============================================================
🎯 路由决策: support
💁 客服专家回复...
【客户服务】
您好!很高兴为您服务~ 😊
(此处省略大量模型输出的内容......)
状态: ✅ 已解决
第十二章 实战项目
智能客服系统架构
把前面学的所有东西整合起来,做一个完整的智能客服系统:
-
Supervisor 分析问题类型
-
技术支持 Agent 处理技术问题
-
销售顾问 Agent 处理产品咨询
-
账单专员 Agent 处理财务问题
-
每个 Agent 都有自己的专业工具
-
支持多轮对话和历史记忆
# ============================================
# 完整案例:Supervisor模式 - 智能客户服务系统
# ============================================
import os
import operator
from typing import Annotated, Literal, TypedDict, Sequence
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage, BaseMessage
from langchain_core.tools import tool
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import create_react_agent
from langgraph.graph.message import add_messages
from langchain_community.llms import Tongyi
import json
print("="*70)
print("Supervisor模式:智能客户服务系统")
print("="*70)
# ============================================
# 第一步:设置环境
# ============================================
os.environ["DASHSCOPE_API_KEY"] = "sk-"
# ============================================
# 第二步:定义State
# ============================================
class SupervisorState(TypedDict):
"""监督者状态"""
messages: Annotated[Sequence[BaseMessage], add_messages]
next: str # 下一个要执行的智能体
# ============================================
# 第三步:为每个专业Agent定义工具
# ============================================
# 技术支持工具
@tool
def check_system_status(component: str) -> str:
"""检查系统组件状态
Args:
component: 组件名称 (database, server, api)
"""
status_db = {
"database": "✅ 数据库运行正常,响应时间 < 10ms",
"server": "⚠️ 服务器负载较高 (CPU 85%)",
"api": "✅ API服务正常,所有端点可访问"
}
return status_db.get(component, f"{component} 状态未知")
@tool
def search_error_code(error_code: str) -> str:
"""查询错误代码含义
Args:
error_code: 错误代码
"""
error_db = {
"500": "内部服务器错误 - 请联系技术团队",
"404": "资源未找到 - 请检查URL",
"403": "访问被拒绝 - 请检查权限",
"401": "未授权 - 请先登录"
}
return error_db.get(error_code, "错误代码未在数据库中")
# 销售工具
@tool
def get_product_info(product_name: str) -> str:
"""获取产品信息
Args:
product_name: 产品名称
"""
products = {
"基础版": "价格:99元/月 | 功能:基础AI对话 | 限制:100次/天",
"专业版": "价格:299元/月 | 功能:高级AI+工具调用 | 限制:1000次/天",
"企业版": "价格:999元/月 | 功能:无限制+专属支持 | 限制:无"
}
return products.get(product_name, "产品不存在")
@tool
def check_promotion(product: str) -> str:
"""查询当前优惠活动
Args:
product: 产品名称
"""
return f"🎉 {product}当前优惠:首月5折!立即订阅可享受此优惠。"
@tool
def calculate_price(product: str, months: int) -> str:
"""计算订阅价格
Args:
product: 产品名称
months: 订阅月数
"""
prices = {"基础版": 99, "专业版": 299, "企业版": 999}
base_price = prices.get(product, 0)
# 计算折扣
discount = 0.5 if months >= 12 else 0.8 if months >= 6 else 1.0
total = base_price * months * discount
return f"💰 {product} {months}个月:原价 {base_price * months}元,折后 {total}元"
# 账单工具
@tool
def query_invoice(order_id: str) -> str:
"""查询发票信息
Args:
order_id: 订单号
"""
invoices = {
"ORD001": "发票已开具 | 金额:299元 | 状态:已发送到邮箱",
"ORD002": "发票处理中 | 预计3个工作日内完成",
"ORD003": "发票信息有误 | 请联系财务部门"
}
return invoices.get(order_id, "订单号不存在")
@tool
def check_payment_status(transaction_id: str) -> str:
"""查询支付状态
Args:
transaction_id: 交易ID
"""
payments = {
"PAY001": "✅ 支付成功 | 金额:299元 | 时间:2025-01-15 10:30",
"PAY002": "⏳ 支付处理中 | 预计5分钟内完成",
"PAY003": "❌ 支付失败 | 原因:余额不足"
}
return payments.get(transaction_id, "交易ID不存在")
@tool
def request_refund(order_id: str, reason: str) -> str:
"""申请退款
Args:
order_id: 订单号
reason: 退款原因
"""
return f"✅ 退款申请已提交 | 订单:{order_id} | 原因:{reason} | 预计3-5个工作日处理"
# ============================================
# 第四步:创建专业Agent
# ============================================
# 模拟Qwen模型(实际使用时替换为真实的ChatTongyi)
class MockQwenLLM:
"""模拟支持工具调用的Qwen"""
def __init__(self, name: str, system_prompt: str):
self.llm = Tongyi(model="qwen-plus", temperature=0.7)
self.name = name
self.system_prompt = system_prompt
def invoke(self, messages):
# 构建完整提示
full_prompt = f"{self.system_prompt}\n\n用户消息:{messages[-1].content if messages else ''}"
response = self.llm.invoke(full_prompt)
return AIMessage(content=response)
# 创建技术支持Agent
tech_llm = MockQwenLLM(
"技术支持",
"你是技术支持专员。专注于解决技术问题、系统错误和故障排查。使用专业的技术语言。"
)
tech_tools = [check_system_status, search_error_code]
def tech_agent_node(state: SupervisorState):
"""技术支持Agent节点"""
print("\n🔧 技术支持Agent工作中...")
# 获取最后一条消息
last_message = state["messages"][-1].content
# 简单的工具选择逻辑(实际应该用LLM判断)
response_parts = []
if "错误" in last_message or "error" in last_message.lower():
# 查找错误代码
for code in ["500", "404", "403", "401"]:
if code in last_message:
result = search_error_code.invoke({"error_code": code})
response_parts.append(result)
break
if "系统" in last_message or "服务器" in last_message:
# 检查系统状态
result = check_system_status.invoke({"component": "server"})
response_parts.append(result)
if not response_parts:
response_parts.append("我是技术支持,请描述您遇到的技术问题,我会帮您解决。")
response = "\n".join(response_parts)
return {"messages": [AIMessage(content=f"【技术支持】\n{response}")]}
# 创建销售Agent
sales_tools = [get_product_info, check_promotion, calculate_price]
def sales_agent_node(state: SupervisorState):
"""销售顾问Agent节点"""
print("\n💼 销售顾问Agent工作中...")
last_message = state["messages"][-1].content
response_parts = []
# 检查产品咨询
products = ["基础版", "专业版", "企业版"]
for product in products:
if product in last_message:
info = get_product_info.invoke({"product_name": product})
promo = check_promotion.invoke({"product": product})
response_parts.append(info)
response_parts.append(promo)
break
# 价格计算
if "价格" in last_message or "多少钱" in last_message:
if not response_parts:
response_parts.append("我们有基础版(99元/月)、专业版(299元/月)、企业版(999元/月)三种套餐。")
if not response_parts:
response_parts.append("您好!我是销售顾问,很高兴为您介绍我们的产品和优惠活动。")
response = "\n".join(response_parts)
return {"messages": [AIMessage(content=f"【销售顾问】\n{response}")]}
# 创建账单Agent
billing_tools = [query_invoice, check_payment_status, request_refund]
def billing_agent_node(state: SupervisorState):
"""账单专员Agent节点"""
print("\n💳 账单专员Agent工作中...")
last_message = state["messages"][-1].content
response_parts = []
# 发票查询
if "发票" in last_message:
response_parts.append("请提供您的订单号,我将为您查询发票状态。示例订单号:ORD001")
# 如果包含订单号
for order_id in ["ORD001", "ORD002", "ORD003"]:
if order_id in last_message:
result = query_invoice.invoke({"order_id": order_id})
response_parts[-1] = result
break
# 支付查询
if "支付" in last_message:
response_parts.append("请提供交易ID,我将为您查询支付状态。")
for pay_id in ["PAY001", "PAY002", "PAY003"]:
if pay_id in last_message:
result = check_payment_status.invoke({"transaction_id": pay_id})
response_parts[-1] = result
break
# 退款
if "退款" in last_message:
response_parts.append("我理解您需要退款。请告诉我订单号和退款原因,我会立即为您处理。")
if not response_parts:
response_parts.append("您好!我是账单专员,可以帮您处理发票、支付和退款等财务问题。")
response = "\n".join(response_parts)
return {"messages": [AIMessage(content=f"【账单专员】\n{response}")]}
# ============================================
# 第五步:创建Supervisor(监督者)
# ============================================
def supervisor_node(state: SupervisorState):
"""监督者节点:决定下一步"""
print("\n👔 Supervisor分析中...")
# 获取最后一条消息
messages = state["messages"]
last_message = messages[-1].content if messages else ""
# 判断是否是用户的第一条消息
is_first_message = len([m for m in messages if isinstance(m, HumanMessage)]) == 1
if is_first_message:
# 第一次:分析用户问题
print(" 分析用户问题类型...")
# 关键词匹配(实际应该用LLM智能判断)
tech_keywords = ["错误", "bug", "崩溃", "error", "系统", "服务器", "API"]
sales_keywords = ["价格", "购买", "产品", "套餐", "订阅", "优惠"]
billing_keywords = ["发票", "支付", "退款", "账单", "费用"]
if any(keyword in last_message for keyword in tech_keywords):
next_agent = "tech_support"
print(" → 路由到:技术支持")
elif any(keyword in last_message for keyword in sales_keywords):
next_agent = "sales"
print(" → 路由到:销售顾问")
elif any(keyword in last_message for keyword in billing_keywords):
next_agent = "billing"
print(" → 路由到:账单专员")
else:
# 默认销售
next_agent = "sales"
print(" → 路由到:销售顾问(默认)")
else:
# 任务完成,结束
next_agent = "FINISH"
print(" → 任务完成")
return {"next": next_agent}
# ============================================
# 第六步:构建图
# ============================================
# 定义路由函数
def route_after_supervisor(state: SupervisorState) -> Literal["tech_support", "sales", "billing", "__end__"]:
"""根据supervisor的决定路由"""
next_agent = state["next"]
if next_agent == "FINISH":
return "__end__"
return next_agent
# 创建图
workflow = StateGraph(SupervisorState)
# 添加所有节点
workflow.add_node("supervisor", supervisor_node)
workflow.add_node("tech_support", tech_agent_node)
workflow.add_node("sales", sales_agent_node)
workflow.add_node("billing", billing_agent_node)
# 流程设计:
# START → supervisor → (tech/sales/billing) → END
workflow.add_edge(START, "supervisor")
workflow.add_conditional_edges(
"supervisor",
route_after_supervisor,
{
"tech_support": "tech_support",
"sales": "sales",
"billing": "billing",
"__end__": END
}
)
# 每个Agent执行完后直接结束(简单版本)
# 复杂版本可以再回到supervisor
workflow.add_edge("tech_support", END)
workflow.add_edge("sales", END)
workflow.add_edge("billing", END)
# 编译
app = workflow.compile()
# ============================================
# 第七步:可视化
# ============================================
print("\n📊 系统架构:")
print("""
用户问题
↓
[Supervisor] ← 智能路由
/ | \\
↓ ↓ ↓
[技术支持][销售][账单]
\\ | /
↓
用户回复
""")
# ============================================
# 第八步:测试系统
# ============================================
test_cases = [
"我遇到500错误,系统无法访问",
"我想了解专业版的价格和优惠",
"我需要查询ORD001的发票",
"服务器好像有问题,能帮我看看吗?",
"基础版和专业版有什么区别?多少钱?",
]
print("\n" + "="*70)
print("开始测试多Agent系统")
print("="*70)
for i, query in enumerate(test_cases, 1):
print(f"\n{'='*70}")
print(f"测试案例 {i}")
print("="*70)
print(f"👤 用户: {query}")
result = app.invoke({
"messages": [HumanMessage(content=query)],
"next": ""
})
# 打印Agent回复
for msg in result["messages"]:
if isinstance(msg, AIMessage):
print(f"\n{msg.content}")
print(f"\n✅ 最终状态: {result['next']}")
print("\n" + "="*70)
print("测试完成!")
print("="*70)
运行结果:
======================================================================
Supervisor模式:智能客户服务系统
======================================================================
📊 系统架构:
用户问题
↓
[Supervisor] ← 智能路由
/ | \
↓ ↓ ↓
[技术支持][销售][账单]
\ | /
↓
用户回复
======================================================================
开始测试多Agent系统
======================================================================
======================================================================
测试案例 1
======================================================================
👤 用户: 我遇到500错误,系统无法访问
👔 Supervisor分析中...
分析用户问题类型...
→ 路由到:技术支持
🔧 技术支持Agent工作中...
【技术支持】
内部服务器错误 - 请联系技术团队
⚠️ 服务器负载较高 (CPU 85%)
✅ 最终状态: tech_support
======================================================================
测试案例 2
======================================================================
👤 用户: 我想了解专业版的价格和优惠
👔 Supervisor分析中...
分析用户问题类型...
→ 路由到:销售顾问
💼 销售顾问Agent工作中...
【销售顾问】
价格:299元/月 | 功能:高级AI+工具调用 | 限制:1000次/天
🎉 专业版当前优惠:首月5折!立即订阅可享受此优惠。
✅ 最终状态: sales
======================================================================
测试案例 3
======================================================================
👤 用户: 我需要查询ORD001的发票
👔 Supervisor分析中...
分析用户问题类型...
→ 路由到:账单专员
💳 账单专员Agent工作中...
【账单专员】
发票已开具 | 金额:299元 | 状态:已发送到邮箱
✅ 最终状态: billing
======================================================================
测试案例 4
======================================================================
👤 用户: 服务器好像有问题,能帮我看看吗?
👔 Supervisor分析中...
分析用户问题类型...
→ 路由到:技术支持
🔧 技术支持Agent工作中...
【技术支持】
⚠️ 服务器负载较高 (CPU 85%)
✅ 最终状态: tech_support
======================================================================
测试案例 5
======================================================================
👤 用户: 基础版和专业版有什么区别?多少钱?
👔 Supervisor分析中...
分析用户问题类型...
→ 路由到:销售顾问(默认)
💼 销售顾问Agent工作中...
【销售顾问】
价格:99元/月 | 功能:基础AI对话 | 限制:100次/天
🎉 基础版当前优惠:首月5折!立即订阅可享受此优惠。
✅ 最终状态: sales
======================================================================
测试完成!
======================================================================
第十三章 进阶话题
1. 持久化和记忆
使用 checkpointer 保存对话状态,使用 thread_id 管理不同会话:
from langgraph.checkpoint.memory import MemorySaver
# 使用 checkpointer 保存对话状态
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
# 使用 thread_id 管理不同会话
config = {"configurable": {"thread_id": "user_123"}}
result = app.invoke(state, config=config)
2. 流式输出
实现打字机效果:
# 方式1:使用 streaming=True 的模型
llm = Tongyi(model="qwen-plus", streaming=True)
for chunk in llm.stream(messages):
print(chunk, end="", flush=True)
# 方式2:使用 app.stream()
for event in app.stream(initial_state):
print(event)
3. 子图(Subgraph)
复杂系统可以拆成多个子图:
# 定义子图
sub_workflow = StateGraph(SubState)
# ... 添加节点和边
sub_graph = sub_workflow.compile()
# 在主图中使用子图作为节点
main_workflow.add_node("sub_process", sub_graph)
4. Human-in-the-Loop
让人类参与决策:
# 设置断点
app = workflow.compile(
checkpointer=memory,
interrupt_before=["sensitive_action"]
)
# 运行到断点会暂停
result = app.invoke(state, config)
# 人工审核后继续
app.invoke(None, config) # 继续执行
5. 调试技巧
# 可视化图结构
print(app.get_graph().draw_mermaid())
# 打印执行过程
for event in app.stream(state, stream_mode="debug"):
print(event)